

CLASI是由字节跳动开发的一个高质量的同时语音翻译系统,类似于专业的人类译员。它能实时翻译语音内容,保持高翻译质量和低延迟。CLASI利用先进的数据策略和多模态检索技术来处理复杂的术语和不清晰的语音信息。
CLASI会根据当前的音频内容,结合外部知识库和历史上下文,生成准确且容错的翻译。它在各种测试数据集上的表现都非常出色,能够传达更多有效信息。
- 翻译策略:CLASI采用了一种创新的策略来平衡翻译的准确性和速度,确保翻译快速且准确。
- 系统架构:系统会处理当前的音频数据,检索相关信息,加载历史上下文,然后输出翻译结果。这一过程不断循环,确保实时翻译。
- 性能:在现实应用中,CLASI的翻译准确性显著高于目前最好的商业和开源系统。例如,从中文到英文的翻译准确率达到81.3%。
CLASI解决了以下几个关键问题:
- 翻译质量与延迟的平衡:
- 传统的语音翻译系统通常使用串联系统,涉及多个模型(如自动语音识别模型、标点模型和机器翻译模型),这些系统常常因错误传播和延迟而影响翻译质量。
- CLASI通过模仿人类译员的策略,采用数据驱动的读写策略来平衡翻译质量和延迟,从而提供高质量的实时翻译。
- 领域术语的翻译:
- 在翻译过程中,特别是在专业领域的翻译中,准确翻译领域术语是一个重大挑战。
- CLASI采用多模态检索增强生成(MM-RAG)模块,通过从外部数据库中检索相关术语和信息来增强翻译质量,确保专业术语的准确翻译。
- 训练数据的匮乏:
- 同时翻译任务的数据稀缺性严重影响了系统的性能提升。
- CLASI通过多阶段训练方法,利用大规模的预训练、持续训练和微调步骤,使模型在少量高质量人类标注数据的辅助下,能够模仿专业人类译员的翻译行为,提高翻译的鲁棒性和质量。
- 人类评估与自动评估的差距:
- 现有的自动评估指标(如BLEU等)可能无法充分反映翻译质量,尤其是长段语音的翻译质量。
- CLASI引入了有效信息比例(VIP)作为新的评估指标,反映了翻译系统在真实场景中传达有效信息的能力,并在这一指标上显著优于现有系统。
CLASI的主要能力
CLASI(Cross Language Agent – Simultaneous Interpretation)在同时翻译领域展现了多种关键能力,使其能够提供高质量的实时语音翻译服务。以下是CLASI的主要能力:
- 高质量实时翻译:
- CLASI能够实时翻译语音,并生成高质量的翻译结果。它模仿专业人类译员的策略,通过数据驱动的读写策略在保证翻译质量的同时,最大限度地减少延迟。
- 多模态检索增强生成(MM-RAG):
- 当遇到专业术语或特殊词汇时,CLASI可以从一个外部知识库中检索相关信息,确保翻译更加准确。
- CLASI具备从外部知识库中检索相关信息的能力,以增强翻译的准确性和一致性。这一多模态检索模块使得系统能够在处理专业术语和特定领域的翻译时表现出色。
- 上下文感知翻译:
- CLASI能够记住并利用之前翻译的内容,确保对话连贯,翻译更自然。
- CLASI可以利用历史上下文信息进行翻译,从而保证翻译的连贯性和准确性。系统能够记住并利用之前的翻译结果和相关上下文进行新的翻译任务。
- 数据驱动的读写策略:
- CLASI采用了模仿人类译员的读写策略,通过数据驱动的方式学习如何在实时翻译中平衡读写操作。这使得系统能够高效地处理长段语音,并保证翻译的准确性。
- 通过模仿人类译员的工作方式,知道什么时候应该停下来听,什么时候应该开始翻译,这样可以保持翻译的质量和速度。
- 多阶段训练:
- CLASI通过预训练、大规模多任务持续训练和人类标注数据的微调,形成了强大的翻译能力。多阶段训练方法确保了系统能够处理不同类型和难度的翻译任务。
- 有效信息比例(VIP)评估:
- CLASI引入了有效信息比例(VIP)作为新的评估指标,专注于评估翻译系统传达有效信息的能力。该系统在VIP指标上显著优于现有的商业和开源系统,证明了其在人类评估中的卓越表现。
- 鲁棒性和适应性:
- CLASI在处理复杂和真实世界的语音翻译任务时表现出色,能够适应各种语音特征,如不流利、口语化和代码混杂等。这使得系统在实际应用中更加实用和可靠。
- 低延迟输出:
- 尽管CLASI专注于提高翻译质量,它仍然能够提供低延迟的翻译输出,确保用户体验的流畅性和实时性。
CLASI的工作原理和技术方法
通过处理当前音频输入,结合外部知识检索和历史上下文信息,实时生成高质量的翻译。
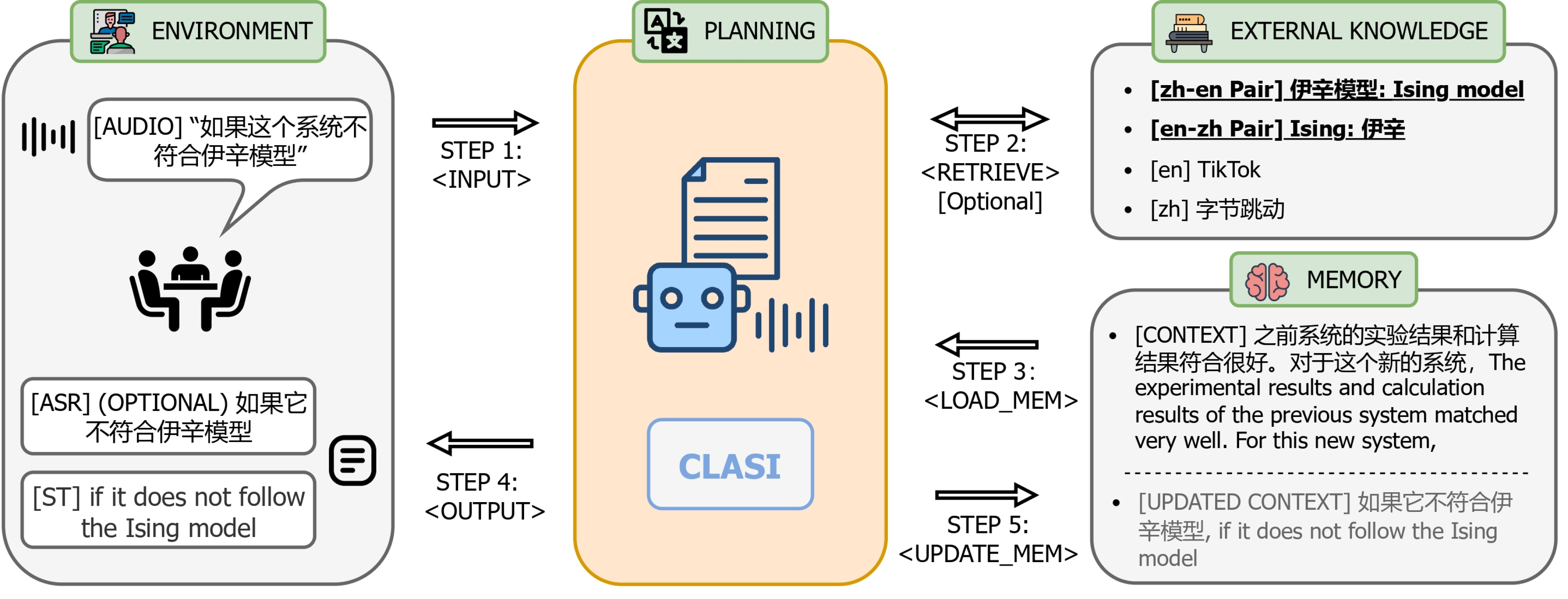

CLASI使用一个结合了音频编码器和大语言模型(LLM)的架构:
- 音频编码器:将输入的语音转换为连续的表示形式。
- 大语言模型(LLM):接收音频编码器生成的表示以及检索到的相关信息和上下文,生成翻译结果。CLASI利用先进的大语言模型来处理复杂的语音输入。LLM能理解并生成自然语言,帮助CLASI在翻译时考虑更多语境信息。LLM还能够处理音频中的错误或不清晰之处,生成容错的翻译结果。
2. 多模态检索增强生成(MM-RAG)
CLASI使用一个多模态检索增强生成(MM-RAG)模块从外部知识库中获取相关信息,特别是针对专业术语或特定领域的内容。这有助于在翻译过程中准确处理专业术语。
这个模块通过以下步骤来增强翻译质量:
- 检索:从外部知识库中检索相关的术语和信息,基于输入语音提取有用的知识。
- 上下文加载:CLASI会保存之前翻译过的内容,形成历史上下文,这有助于理解和翻译当前的音频输入。在翻译新内容时,CLASI会参考这些历史数据,确保翻译的一致性和连贯性。
- 生成:大语言模型根据输入语音和上下文生成翻译结果。
- 例如,当系统遇到“伊辛模型”这样的术语时,会从知识库中检索对应的翻译“Ising model”,确保翻译的准确性。
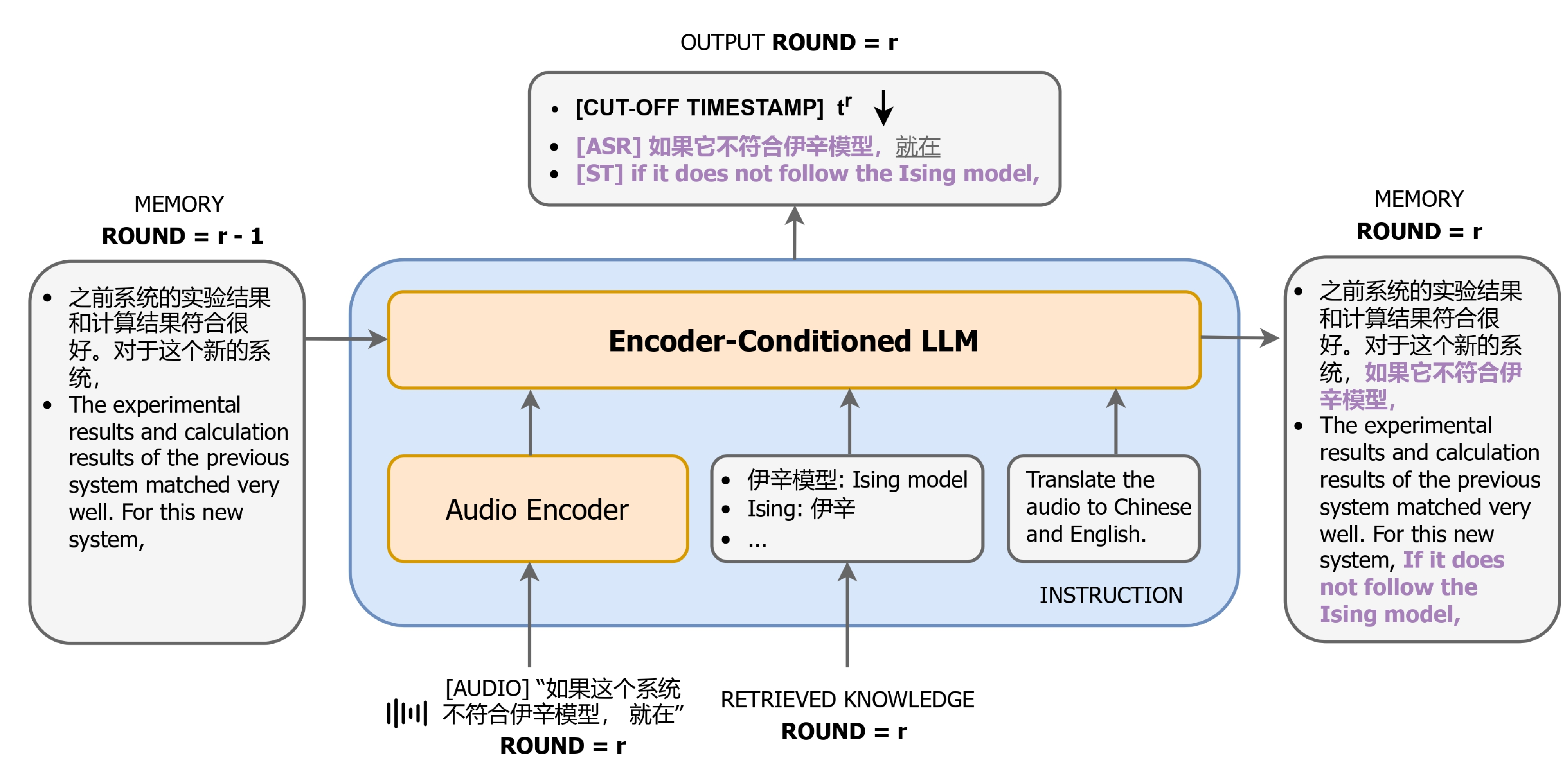

CLASI模仿人类译员的工作方式,采用数据驱动的读写策略来平衡翻译质量和延迟:
- 读策略:CLASI会读取当前的音频输入,并将其转化为文本。
- 写策略:在生成翻译时,CLASI考虑了多种因素,包括当前输入、历史上下文和检索到的外部信息,从而平衡翻译质量和延迟。
- 听和译:系统会等待完整的语义单元(如句子或短语)后再进行翻译,确保翻译的连贯性和准确性。
4. 多阶段训练
CLASI通过三个阶段的训练来提升其翻译能力:
- 预训练:分别对大语言模型和音频编码器进行大规模数据的预训练。
- 多任务持续训练:结合自动语音识别(ASR)、语音翻译(ST)和文本翻译(MT)任务,使用大规模配对数据进行训练。
- 多任务监督微调:使用高质量的人类标注数据进行微调,模仿专业人类译员的翻译行为,进一步提升系统的鲁棒性和翻译质量。
5. 有效信息比例(VIP)评估
为了评估翻译质量,CLASI采用了有效信息比例 (VIP) 这一指标。VIP用来评估翻译系统在实际使用中能传达多少有效信息。
- VIP:衡量翻译结果中有效信息的比例,以此评估系统的实际翻译效果。
- 在实验中,CLASI的VIP显著高于其他商业或开源系统,这表明CLASI能更有效地传达原始语音中的关键信息。
详细步骤
步骤1:输入处理
- 语音信号输入:系统接收输入的语音信号。
- 音频特征提取:音频编码器将语音信号转换为连续的特征表示。
步骤2:检索和上下文加载
- 检索相关信息:多模态检索模块从外部知识库中检索相关术语和信息。
- 加载上下文信息:系统加载历史翻译结果和检索到的相关信息,作为当前翻译的上下文。
步骤3:翻译生成
- 生成翻译结果:大语言模型接收音频特征表示、检索信息和上下文,生成翻译结果。
- 处理语义单元:系统根据完整的语义单元(如句子或短语)进行翻译,确保输出的连贯性。
步骤4:结果输出和记忆更新
- 输出翻译结果:系统将翻译结果输出给用户。
- 更新记忆模块:将当前翻译结果保存到记忆模块中,以便后续翻译任务使用。
- 循环处理:系统不断重复以上步骤,实时处理新的音频输入,更新翻译结果和历史上下文。
实验结果
1. 卓越的翻译质量
- CLASI在多个评估指标上均表现优异,特别是在有效信息比例(VIP)评估中显著优于现有的商业和开源系统。
- 在实验中,CLASI在中文到英文(zh-en)和英文到中文(en-zh)的翻译中分别达到了81.3%和78.0%的VIP评分,远超其他系统的35.4%和41.6%。
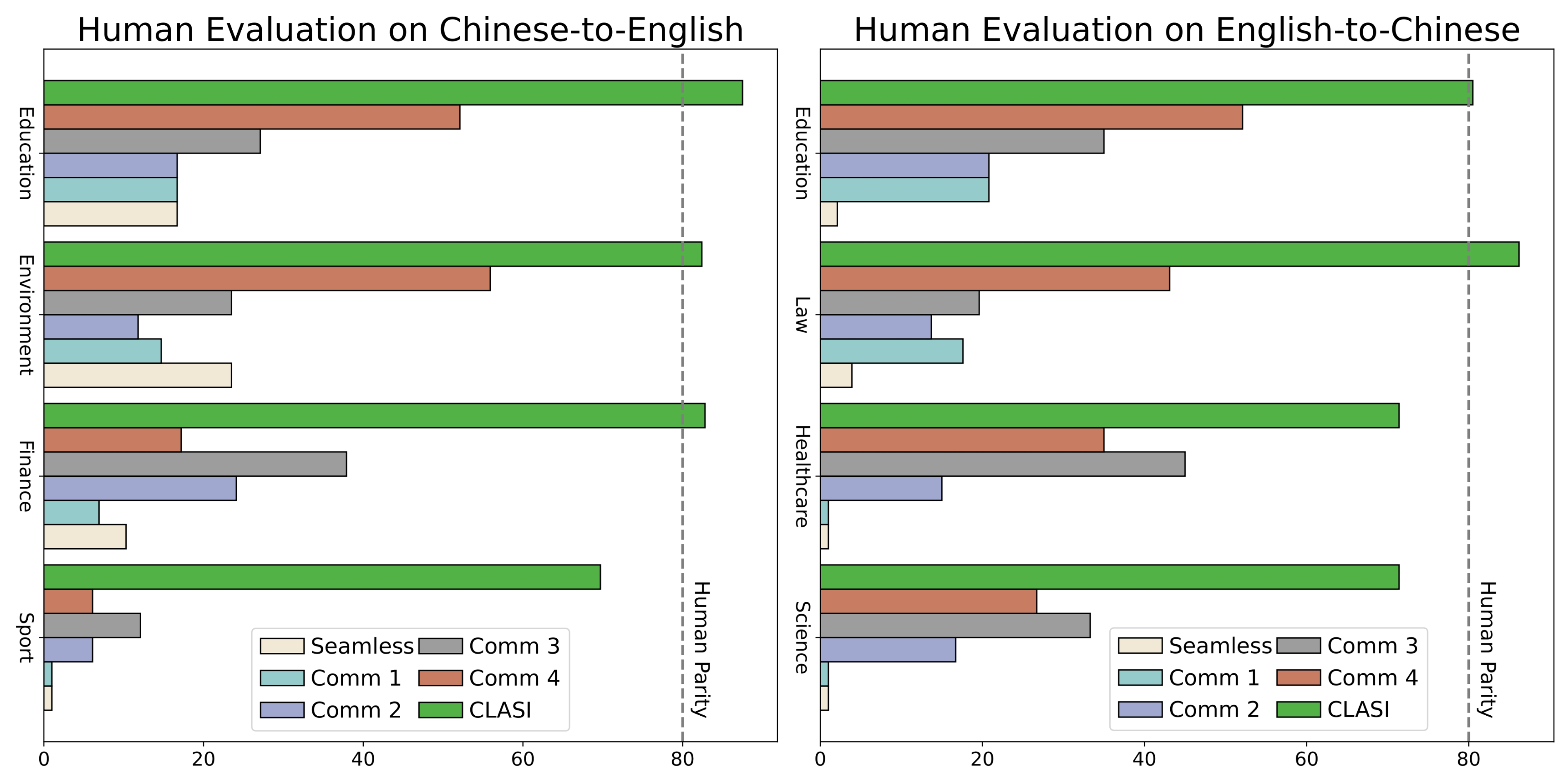

- CLASI能够在保持高翻译质量的同时,实现低延迟输出。其在平均滞后(AL)、长度自适应平均滞后(LAAL)和首字出现滞后(FLAL)等延迟指标上表现优于大多数商用系统。
- 在真实场景数据集(RealSI)和句子级别数据集(CoVoST2)上的测试表明,CLASI的延迟性能足以满足实际应用需求,同时保持了高翻译质量。
3. 鲁棒性和适应性
- CLASI在处理复杂的真实语境时表现出色,包括不流利的语音、口语化表达和多语言混杂的情况。
- 案例分析显示,CLASI能够准确识别并翻译专业术语和流行词汇,避免了常见的误译问题。
4. 创新的技术方法
- CLASI采用了数据驱动的读写策略、模仿人类译员的翻译方法、多模态检索增强生成(MM-RAG)和多阶段训练等一系列创新技术,显著提升了系统的翻译质量和效率。
- 通过结合预训练、多任务持续训练和人类标注数据的微调,CLASI实现了在少量高质量数据上的高效学习,确保其在各种复杂任务中的卓越表现。
5. 实际应用潜力
- CLASI具备广泛的实际应用潜力,可以用于会议、在线视频、在线游戏等多种场景,显著促进跨语言交流。
- 通过高效的实时翻译服务,CLASI能够帮助用户更好地理解和交流不同语言的内容,提高工作和生活中的沟通效率。
演示效果
即兴对话 旅游
即兴对话 健身
朗读 赤壁赋
即兴对话 星座
角色扮演 三国
即兴对话 生活爱好
即兴对话 生活爱好
绕口令
Chinese 中文 → English 英语
English 英语 →Chinese 中文
项目及演示:https://byteresearchcla.github.io/clasi/
论文:https://byteresearchcla.github.io/clasi/technical_report.pdf