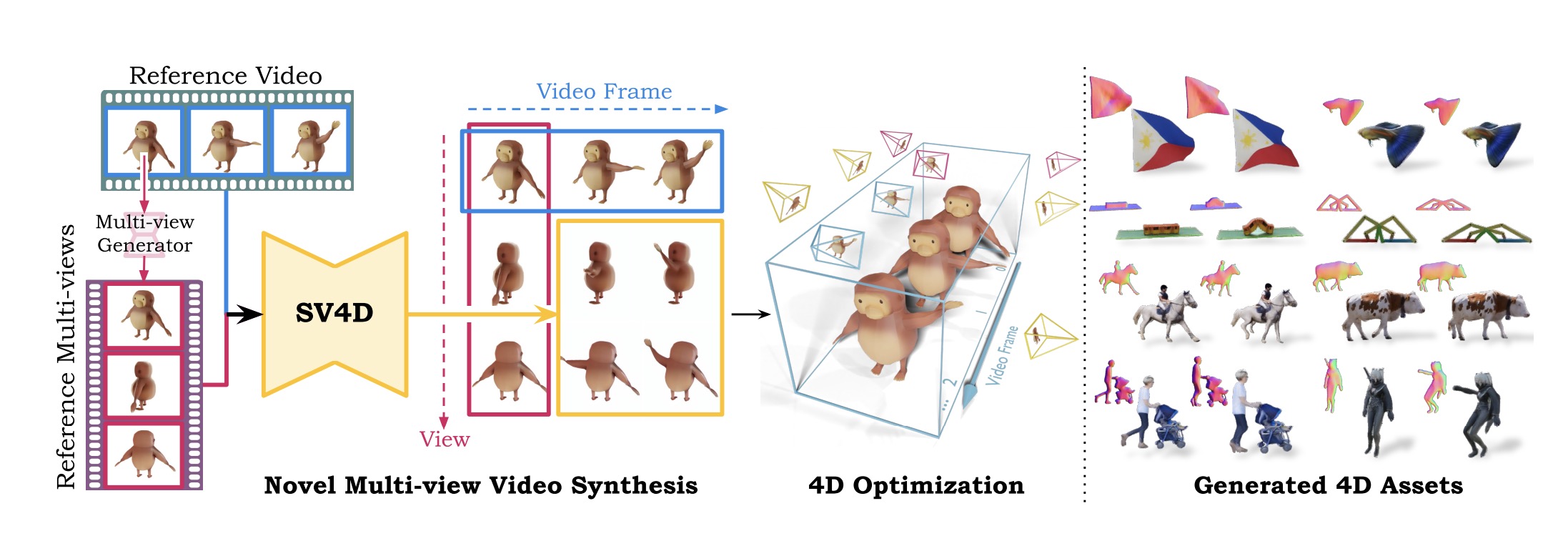
Stability AI 宣布推出 Stable Video 4D(SV4D),这是一款创新模型,用户可以上传单个视频并生成八个新角度的动态新视角视频。
与以往需要从图像扩散模型、视频扩散模型和多视角扩散模型中取样的方法不同,SV4D 能够同时生成多个新视角视频,大大提高了空间和时间轴上的一致性。这不仅确保了多个视角和时间戳中对象外观的一致性,还实现了更轻量级的4D优化框架,无需使用多个扩散模型进行繁琐的得分蒸馏采样(SDS)。
Stable Video 4D 可以在大约40秒内生成跨越8个视角的5帧视频,整个4D优化过程大约需要20到25分钟。该技术在游戏开发、视频编辑和虚拟现实领域具有广泛的应用前景。专业人员可以利用此技术从多个视角可视化对象,增强产品的真实感和沉浸感。


1. 多视图视频生成
SV4D的主要功能之一是从单个视频生成多视角的视频帧。这意味着给定一个单视角的视频,SV4D能够生成该视频中对象在多个不同视角下的帧,并确保这些帧在时间上的一致性。这一功能在以下几个方面表现出色:
- 视图一致性:SV4D在生成的每一帧中,确保所有视角的图像都在空间上保持一致。这是通过模型中的视图注意力模块实现的。
- 时间一致性:SV4D还确保在不同时间点的视角图像之间保持一致。这是通过模型中的帧注意力模块实现的。
2. 4D 表示优化
SV4D不仅仅是生成多视角的视频帧,它还能够使用这些生成的视角视频来优化动态3D对象的4D表示。具体来说,SV4D通过以下步骤实现这一点:
- 参考视图生成:首先,通过现有的多视图生成模型(如SV3D)生成初始帧的参考视图。
- 多帧生成:然后,SV4D联合生成其余帧的视角图像,确保这些图像在时间和视角上的一致性。
- 动态4D优化:最后,利用生成的多视角视频,通过优化算法进一步提升动态3D对象的表示。这避免了以往方法中繁琐的基于SDS的优化过程。
3. 混合采样方案
为了处理长视频输入,SV4D采用了一种混合采样方案。该方案在以下方面发挥了重要作用:
- 内存效率:通过逐步处理输入视频的一个交错子集,避免了生成全图像网格所需的巨大内存需求。
- 一致性保持:在处理子集时,保持输出图像网格的一致性。具体方法包括先生成一组稀疏的锚点帧,然后以这些锚点帧为新参考视图密集采样中间帧。
4. 自适应的引导缩放
在生成过程中,SV4D采用了一种自适应的引导缩放策略,以确保生成的图像在帧轴和视图轴上的一致性。这种策略结合了帧轴的线性增长和视图轴的三角波形变化,有效避免了图像过度锐化或饱和的问题。
使用的方法

SV4D使用了最新的扩散模型技术来实现高质量的视频生成和多视图生成。扩散模型是一类生成模型,通过逐步去噪的方法生成数据。具体到SV4D,使用了Stable Video Diffusion (SVD) 和 SV3D 模型,并在此基础上进行了改进:
- 视频扩散模型:使用Stable Video Diffusion (SVD)生成连续的、时间一致的视频帧。
- 多视图扩散模型:使用SV3D生成同一时间点的多视角图像,确保视角之间的一致性。

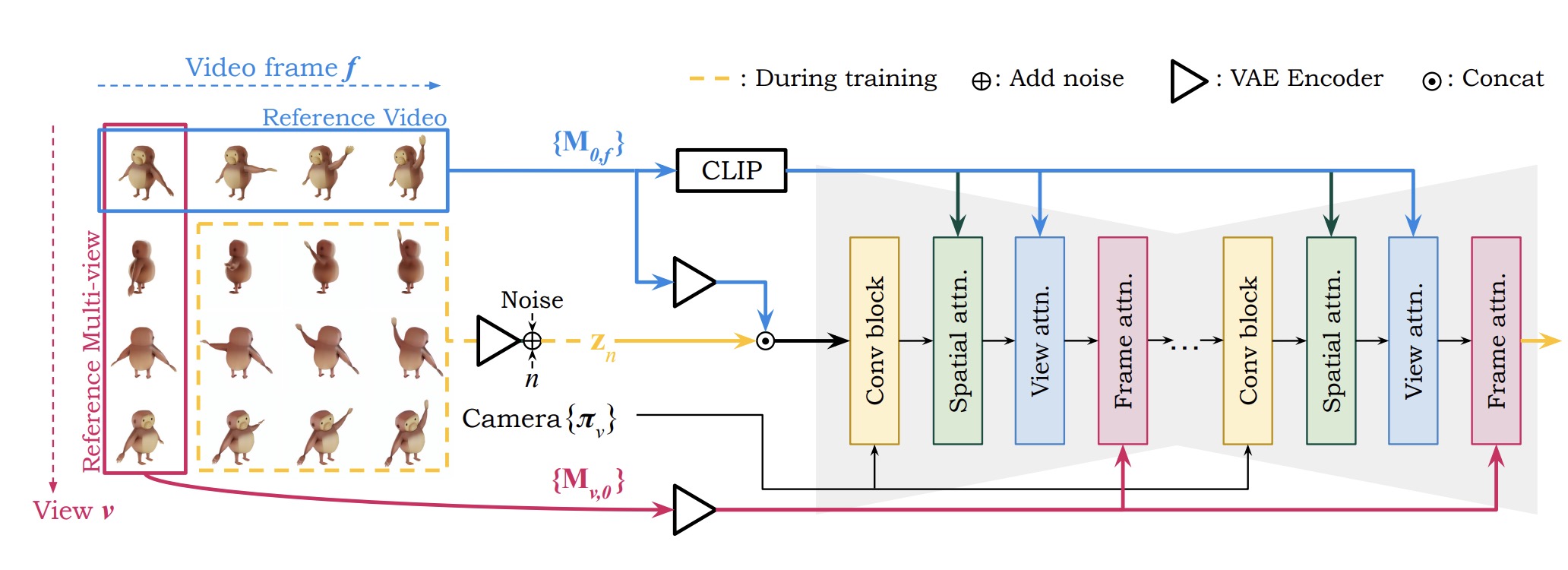
2. 视图注意力和帧注意力模块
为了在时间和视角上保持生成内容的一致性,SV4D在扩散模型中加入了视图注意力和帧注意力模块:
- 视图注意力模块:在生成每一帧时,视图注意力模块确保该帧的所有视角图像在空间上的一致性。
- 帧注意力模块:在生成每个视角图像时,帧注意力模块确保该视角的所有帧在时间上的一致性。

为了训练SV4D,研究者从现有的Objaverse数据集中策划了一个新的4D数据集,命名为ObjaverseDy。这个数据集包含了大量的动态3D对象,研究者通过以下步骤进行策划和处理:
- 筛选对象:过滤掉动画帧过少或运动不足的对象,确保每个对象都具有足够的动态信息。
- 灵活的相机距离选择:动态调整相机与对象之间的距离,以确保对象始终在渲染图像的帧内。
- 动态时间采样:调整时间采样步长,以确保帧之间的运动足够明显。
4. 混合采样方案
SV4D采用了一种混合采样方案,以处理长视频输入并保持输出图像网格的一致性:
- 锚点帧生成:首先,生成一组稀疏的锚点帧,这些锚点帧作为新参考视图,用于后续的密集采样。
- 密集采样:以锚点帧为参考,密集采样中间帧,确保在时间和视角上的平滑过渡。
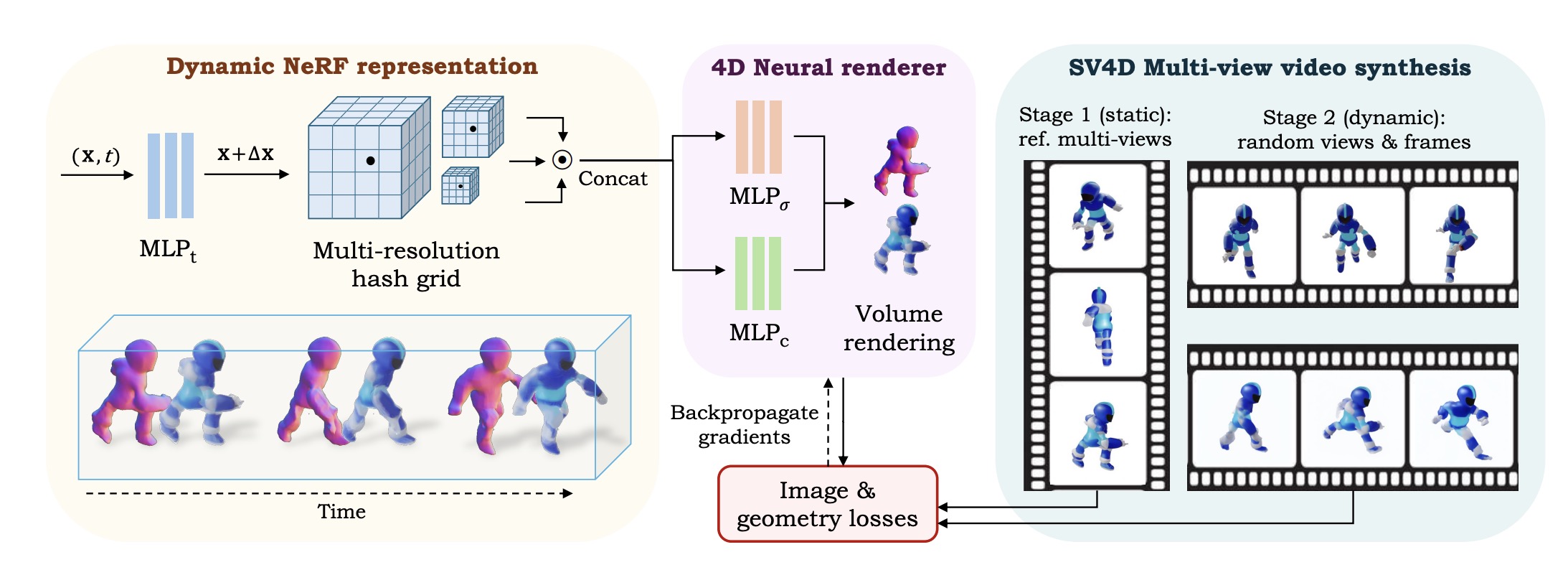
5. 4D 优化
使用SV4D生成的多视图视频来优化动态3D对象的4D表示,具体步骤如下:
- 初始优化:先使用参考多视图图像优化静态NeRF表示。
- 动态优化:然后解冻时间变形网络,并使用随机采样的视图和帧进行优化。
6. 自适应的引导缩放
在生成过程中,SV4D采用了一种自适应的引导缩放策略,以确保生成的图像在帧轴和视图轴上的一致性:
- 帧轴线性增长:在时间轴上采用线性增长的引导缩放,确保从初始帧到最后一帧的一致性。
- 视图轴三角波形变化:在视图轴上采用三角波形变化,避免过度锐化或饱和。
7. 多重损失函数
在优化过程中,SV4D使用了多种损失函数来提高生成内容的质量和一致性:
- 像素级MSE损失:用于减少生成图像与真实图像之间的像素差异。
- 感知损失:使用LPIPS损失来衡量生成图像在视觉上的相似性。
- 几何先验:包括单目法线损失、双边深度和法线平滑损失,以确保生成的3D对象具有平滑的表面和一致的几何形状。
实验结果
定量比较
- 视频帧一致性(FVD-F):SV4D在视频帧一致性方面表现显著优于现有方法。例如,与SV3D和STAG4D相比,SV4D的FVD-F分别降低了31.5%和21.4%。
- 多视角一致性(FVD-V):SV4D在多视角一致性上也表现优异,生成的视频在不同视角之间更加一致。
- 4D一致性(FVD-Diag和FV4D):SV4D在4D一致性评估中同样表现突出,证明其生成的多视角视频具有更好的时间和空间一致性。
定性比较
- 视觉比较:SV4D生成的视频在几何和纹理细节上更加忠实于输入视频,并且在多帧和多视角上一致性更好。相比之下,其他方法生成的视频可能会出现几何失真和纹理不一致的问题。
- 用户研究:在用户研究中,SV4D的生成结果被参与者显著更喜欢。在多视角视频合成的用户偏好测试中,SV4D的结果比SV3D、Diffusion2和STAG4D更受青睐。
应用前景
- 游戏开发:SV4D在游戏开发中可以用于生成多视角的动态对象,提升游戏的真实感和沉浸感。
- 视频编辑:在视频编辑中,SV4D可以提供高质量的多视角视频素材,增强编辑的灵活性和创意。
- 虚拟现实:在虚拟现实领域,SV4D可以用于生成更真实和一致的虚拟对象,提升用户的沉浸体验。
性能总结表
| 性能指标 | SV4D表现 | 对比方法表现 |
|---|---|---|
| 生成速度 | 40秒内生成8视角的5帧视频 | 传统方法需要数小时 |
| 多视角一致性 | FVD-V显著低于对比方法 | SV3D和STAG4D一致性较差 |
| 时间一致性 | FVD-F显著低于对比方法 | SV3D和STAG4D一致性较差 |
| 图像质量 | LPIPS和CLIP-S表现良好 | Diffusion2和其他方法可能模糊 |
| 4D一致性 | FVD-Diag和FV4D表现优异 | 其他方法一致性较差 |
| 用户偏好 | 73.3%用户偏好SV4D生成结果 | SV3D、Diffusion2和STAG4D偏好低 |
项目及演示:https://sv4d.github.io/
模型下载:https://huggingface.co/stabilityai/sv4d