

- Meta发布了新的Llama 3.1模型,包括期待已久的405B。
- 这些模型具有改进的推理能力、128K token上下文窗口,并支持8种语言。
- Llama 3.1 405B在多项任务上与领先的闭源模型竞争。
- 训练405B模型使用了超过16K的NVIDIA H100 GPU,历时数月。
- Llama 3.1 8B和70B模型在性能和安全性上优于前代。
- 更新的许可证允许使用Llama模型的输出改进其他模型。
模型大小:
- 8B: 适用于消费者级GPU的高效部署和开发
- 70B: 适用于大规模AI本地应用
- 405B: 适用于合成数据、LLM作为评审和蒸馏
新特性:
- 128K的长上下文长度(之前为8K)
- 多语言支持,涵盖英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语
- 工具使用能力,支持搜索和Wolfram Alpha的数学推理
- 更宽松的许可,允许使用模型输出改进其他LLMs
模型亮点
- Llama 3.1 405B:
- 参数规模:4050亿参数。
- 上下文长度:支持长达128K的上下文。
- 多语言支持:支持八种语言。
- 功能优势:在一般知识、可控性、数学、工具使用和多语言翻译方面表现优异。
- 增强版8B和70B模型:
- 多语言:提供强大的多语言支持。
- 上下文扩展:上下文长度显著延长至128K。
- 高级用例:支持长文本总结、多语言对话代理和编程助手等高级应用。
- 多功能支持多语言支持:
- Llama 3 天然支持多语言处理,预训练数据包括了大约 50% 的多语言 token,能够处理和理解多种语言。
编程和推理:
- Llama 3 拥有强大的编程能力,可以生成高质量的代码。它能够理解编程语言的语法和逻辑,生成复杂的代码结构,并在编程任务中表现出色。
- Llama 3 具备出色的推理能力,能够处理复杂的逻辑推理任务。它在解答问题、分析和推断方面表现优异,能够解决涉及逻辑和推理的复杂问题。
工具使用:
- 模型能够集成和使用多种工具,支持在零样本条件下进行工具调用和操作。
- Llama 3 能够集成和使用多种工具来完成任务。这使得模型可以进行多种功能的组合应用,如文本分析、代码生成、数据处理等,提升了任务处理的灵活性和效率。
4. 长上下文处理
上下文窗口扩展:
- 最大支持 128K 个 token 的上下文窗口,使得模型能够处理非常长的文本输入。
长上下文预训练:
- 在预训练的最后阶段,模型逐步适应更长的上下文窗口,以提高长文本处理的能力。
5. 多模态扩展
图像、视频和语音功能:
- 通过组合方法将图像、视频和语音功能整合到模型中,初步实验表明在图像、视频和语音识别任务上具有竞争力的表现。
多模态模型:
- 开发了支持图像识别、视频识别和语音理解能力的多模态模型,这些模型仍在开发中,尚未广泛发布。
模型评估与架构
模型评估
Meta对Llama 3.1系列模型进行了全面的评估,使用了150多个基准数据集,涵盖了多种语言和任务。这些评估包括对比Llama 3.1与市场上领先的AI模型(如GPT-4、Claude 3.5 Sonnet)的性能。实验结果表明,Llama 3.1不仅在通用知识、可控性、数学、工具使用和多语言翻译等方面表现出色,而且在多个实际场景中与闭源模型表现相当。
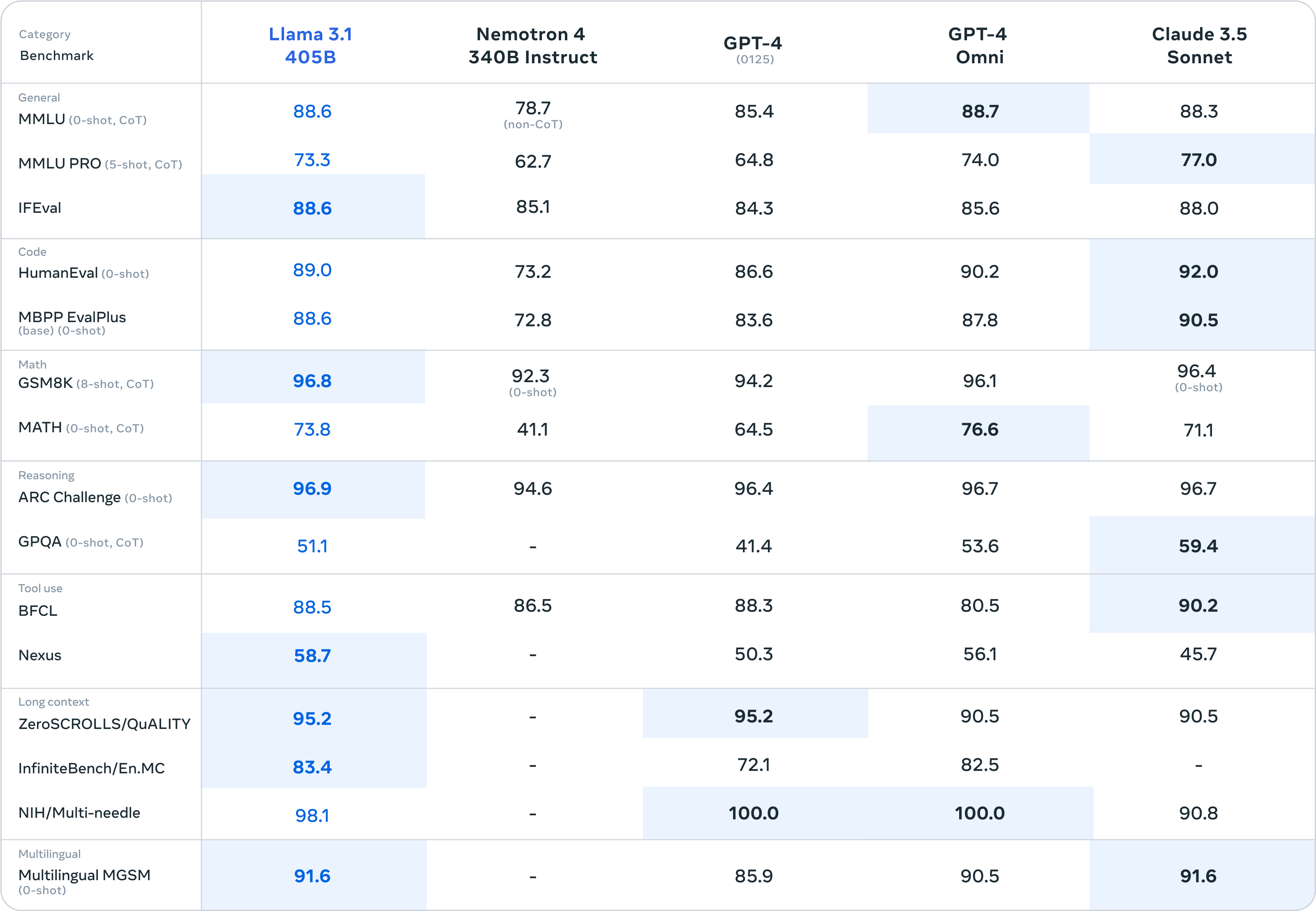
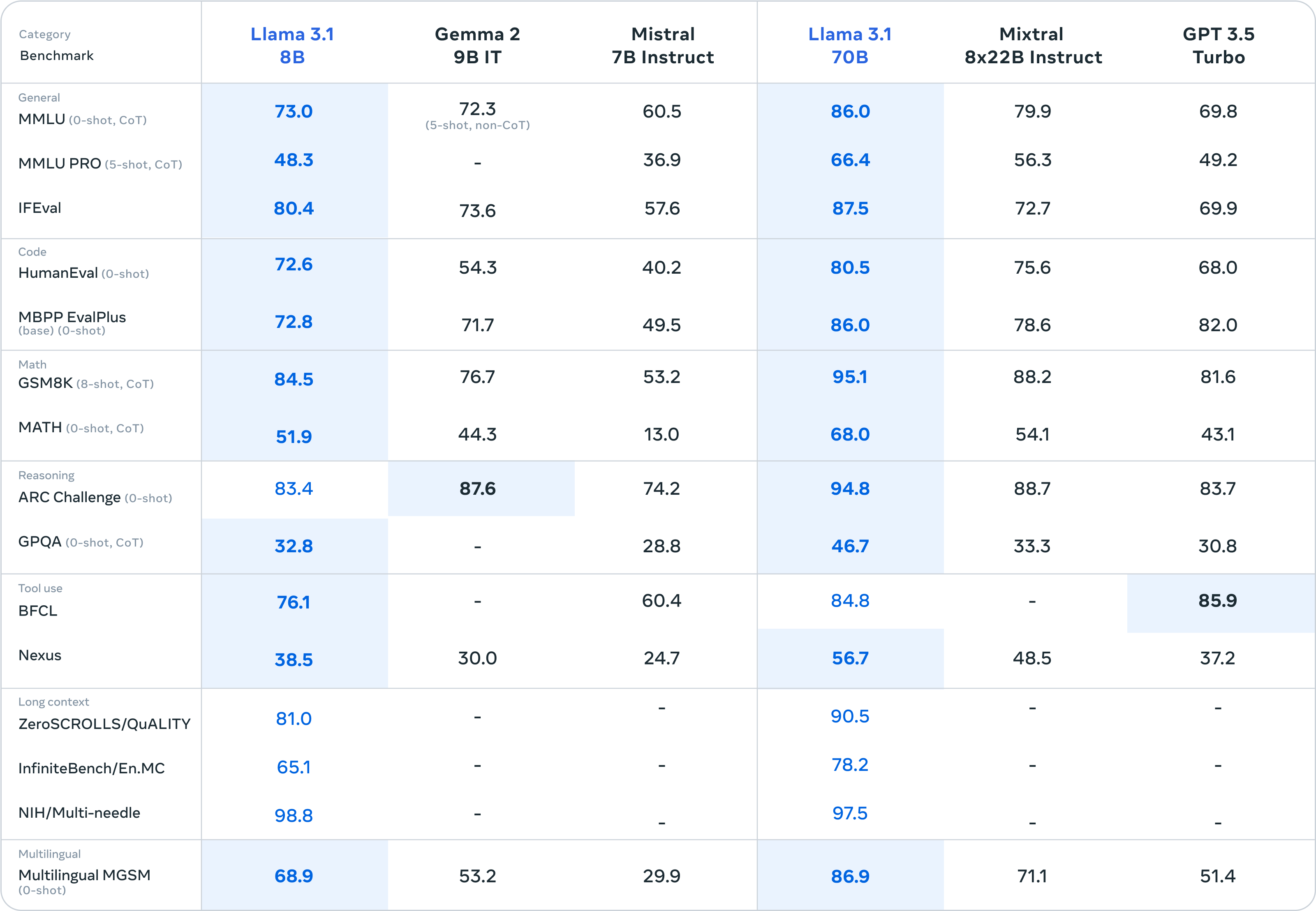
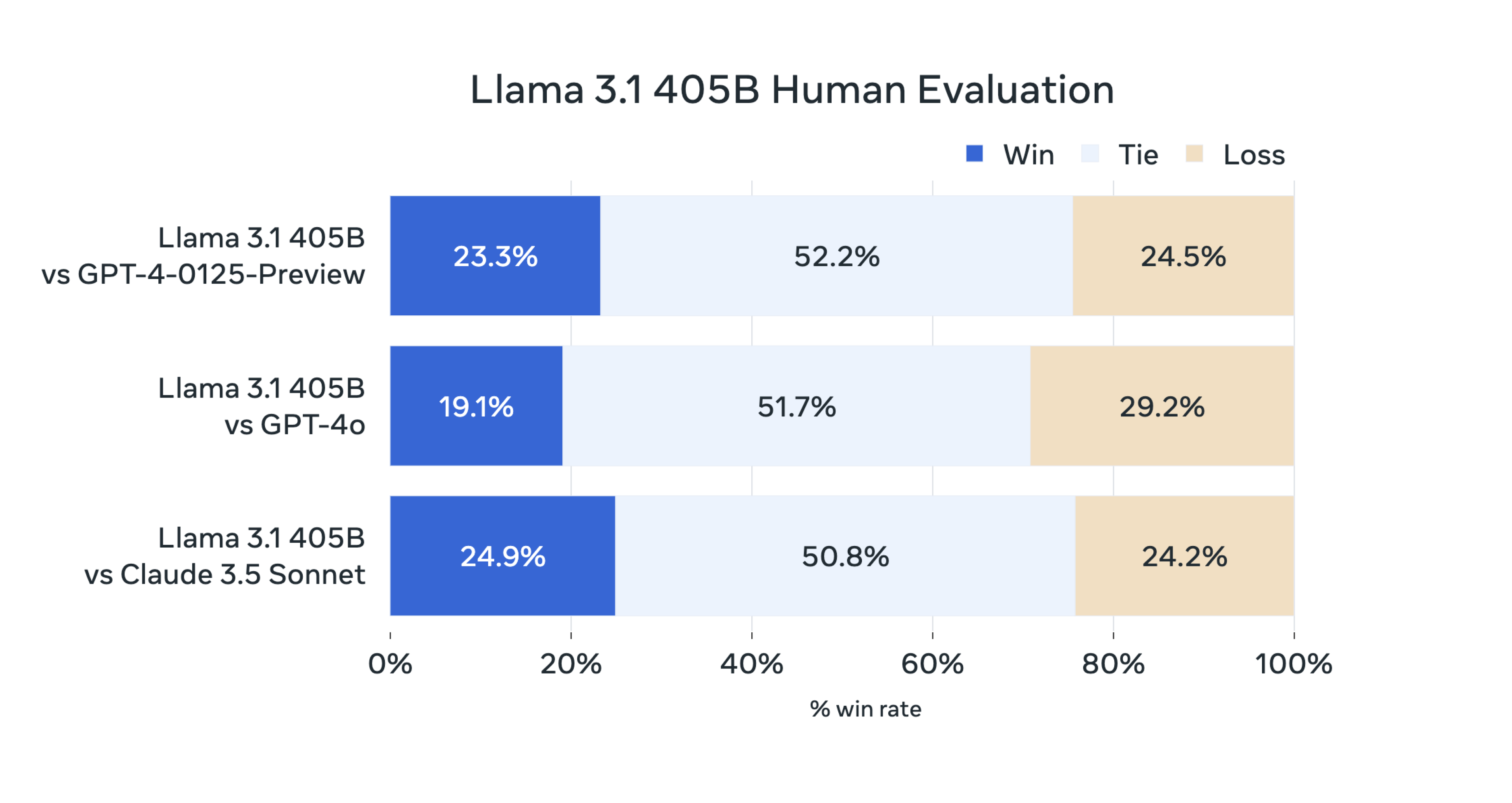


模型架构
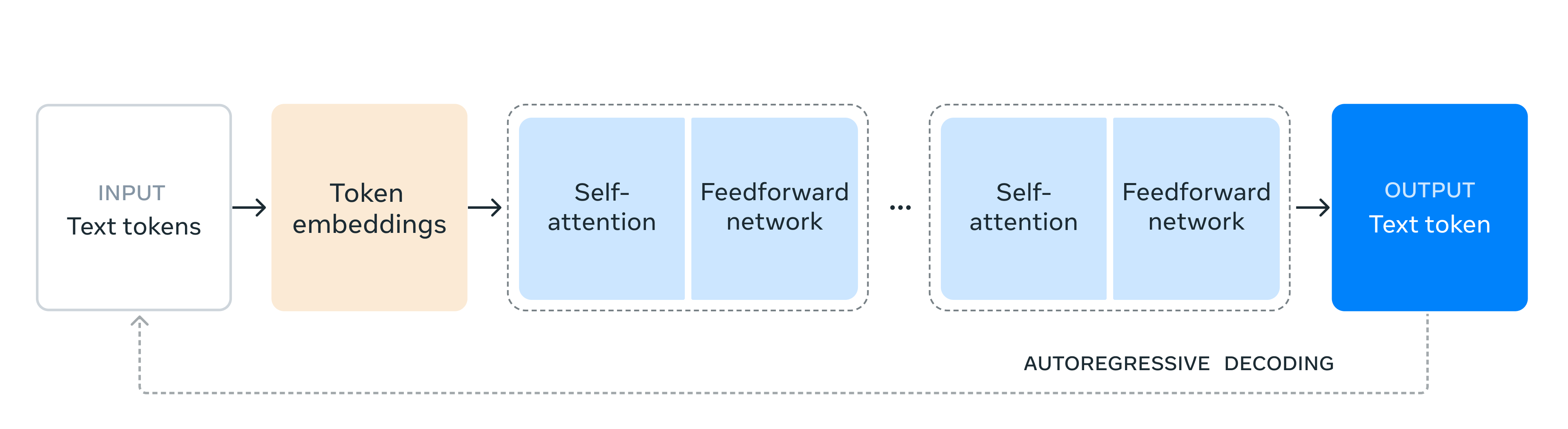

- 训练规模:Llama 3.1 405B是Meta迄今为止最大的模型,训练数据量超过15万亿个token。为了实现这一规模的训练,Meta优化了整个训练堆栈,使用超过16,000个H100 GPU进行训练,使405B成为首个在如此规模上训练的Llama模型。
- 设计选择:
- 模型结构:采用标准的解码器-仅变换器模型架构,避免了专家混合模型,以确保训练的稳定性。
- 迭代后训练:每轮迭代使用监督微调和直接偏好优化,生成高质量的合成数据,逐步提高各项能力的性能。
- 数据质量:
- 预训练数据:改进了预处理和数据筛选流程,确保了更高质量的预训练数据。
- 后训练数据:采用严格的质量保证和过滤方法,提高后训练数据的质量。
- 量化技术:
- 数值优化:将模型从16位(BF16)量化到8位(FP8),有效降低了计算需求,使模型能够在单个服务器节点上运行。
- 指令和对话微调:
- 多轮对齐:通过多轮对齐,包括监督微调、拒绝采样和直接偏好优化,提高模型在响应用户指令时的详细性和安全性。
- 合成数据生成:使用合成数据生成技术,生产出高质量的微调数据,支持模型在128K上下文窗口内的高效表现。
关键技术突破
- 模型量化:通过将模型量化到8位,提高了推理效率,降低了计算成本。
- 多语言支持:增强了模型在多语言环境中的适用性,支持跨语言任务。
- 上下文长度扩展:大幅扩展了上下文长度,提高了长文本处理和复杂任务的能力。
马克·扎克伯格(Mark Zuckerberg)发文强调了为什么他认为开源AI对开发者、Meta和整个世界都有好处。他指出,开源软件,如Linux,已经证明了其在性能、安全性和生态系统方面的优势。扎克伯格认为,AI的发展将类似于Linux的发展,开源AI将逐渐成为行业标准。
他认为开源软件如Linux已经证明了其在许多方面的优势,AI也会走上类似的道路。Meta推出了新的开源AI模型Llama 3.1,并与多家公司合作提供支持服务,推动开源AI成为行业标准。开源AI不仅对Meta有利,还能促进全球技术的平等发展和应用。