

EchoMimic 是由蚂蚁集团开发的一种通过音频和面部标志生成逼真的肖像动画视频的新方法。与传统的方法不同,EchoMimic 不仅可以单独使用音频或面部标志点,还可以结合两者进行视频生成。从而提高了生成视频的稳定性和自然度。
解决了什么问题
EchoMimic 解决了以下两个主要问题:
- 仅由音频驱动的不稳定性:
- 传统方法仅使用音频信号来驱动图像生成视频,然而音频信号相对较弱,容易导致生成的视频不稳定。
- EchoMimic 通过结合音频和面部标志的输入,提高了视频生成的稳定性,使得输出更加平滑和一致。
- 仅由面部关键点驱动的不自然性:
- 另一种传统方法是仅使用面部关键点来驱动图像生成视频,这虽然在驱动上更稳定,但由于过多依赖关键点信息,生成的结果往往显得不够自然。
- EchoMimic 通过平衡音频和面部标志的输入,使生成的视频更符合实际的面部运动和表情变化,从而提高了自然度。

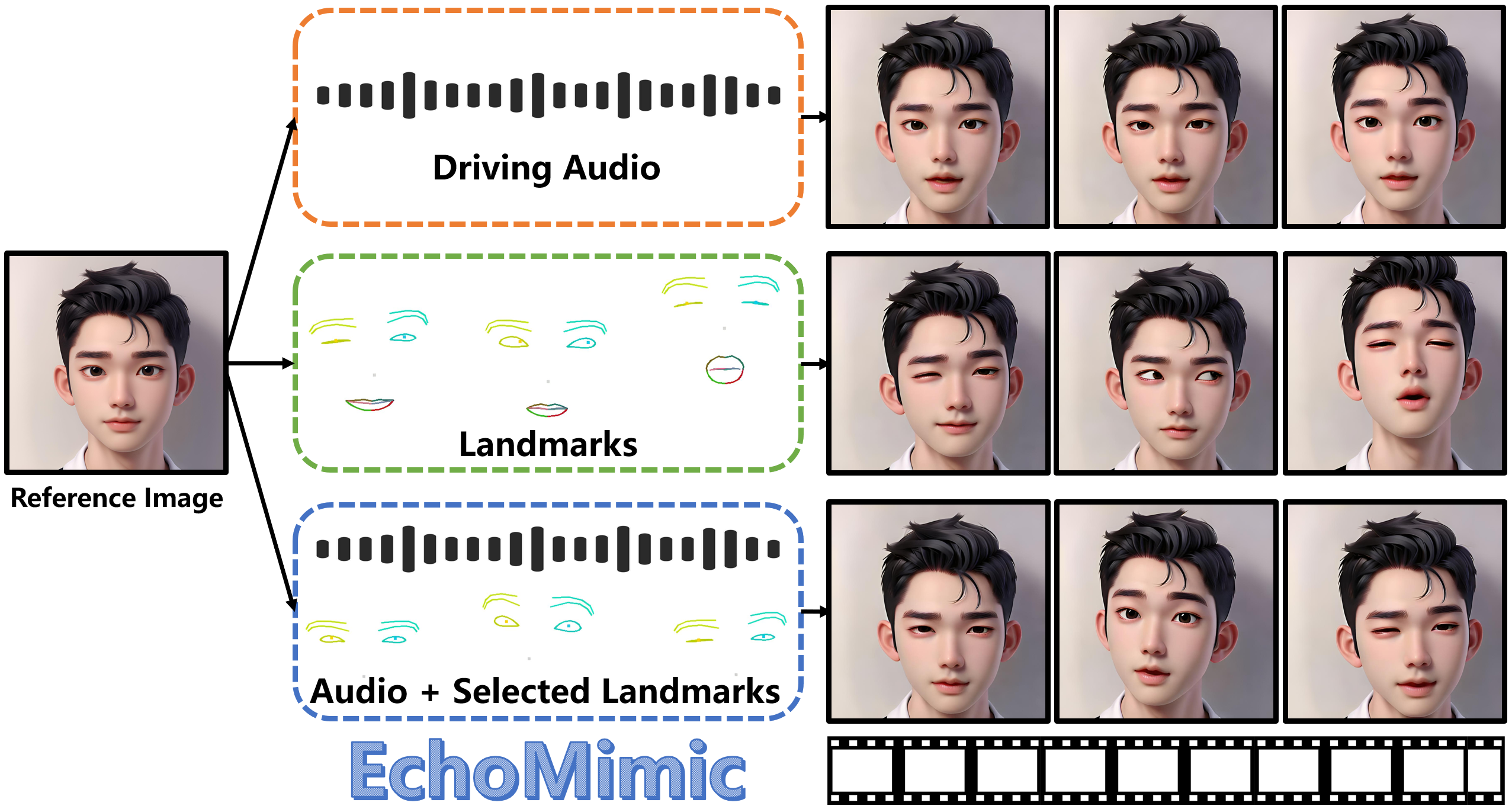
效果与优势
- 稳定性:通过结合音频和面部标志,EchoMimic 提高了生成动画的稳定性,减少了抖动和失真。
- 自然度:融合音频和面部标志特征,使生成的面部动画更加符合自然的面部运动和表情变化。
- 性能:在各种公共数据集和自有数据集上,EchoMimic 的表现优于现有的其他方法。
面部标志点是什么
面部标志点(Facial Landmarks)是指在面部图像上标注的一组特定点,用于表示面部的关键特征和结构。它们通常位于面部的轮廓、眼睛、鼻子、嘴巴等位置。这些点可以帮助计算机视觉算法更好地理解和分析面部表情、动作和姿态。面部标志点通常用于人脸识别、表情识别、面部动画等领域。
面部标志点的具体位置
面部有68个主要标志点,通常包括:
- 17个沿着面部轮廓(从左耳到右耳,通过下巴)
- 5个在每只眼睛周围(总共10个)
- 9个在每条眉毛周围(总共18个)
- 9个在鼻子周围
- 12个在嘴唇周围(外圈)
- 8个在嘴唇内部(内圈)
面部标志点的数量和位置可以根据不同的应用和算法有所不同,但通常包括以下几个主要区域:
- 面部轮廓:沿着面部的外部边缘,从下巴到额头。
- 眼睛:包括每只眼睛的内外角、上眼睑和下眼睑的多个点。
- 眉毛:每条眉毛的多个关键点,表示眉毛的形状和位置。
- 鼻子:鼻尖、鼻翼和鼻梁的多个点。
- 嘴巴:嘴唇的外部轮廓和内部轮廓的多个点,包括上下嘴唇。
- 面部中心点:一些算法还包括额头、脸颊和其他面部区域的中心点。
面部标志点的应用
- 面部识别:通过标志点的位置和形状,识别人脸的身份。
- 表情识别:分析标志点的变化,识别面部表情和情感。
- 面部动画:将面部标志点用于驱动虚拟角色的面部动画,使其模仿真人的表情和动作。
- 增强现实(AR):在面部标志点的位置上叠加虚拟元素,如滤镜和特效。
- 医学成像:用于面部结构的分析和手术规划。
EchoMimic的主要功能
EchoMimic 的主要功能围绕着生成逼真的肖像动画视频,通过结合音频输入和面部标志来实现。以下是其主要功能的详细介绍:
1. 单独通过音频生成肖像视频
- 功能描述:EchoMimic 可以仅通过音频输入生成肖像动画视频。这种方法通过分析音频信号中的语调、节奏和其他特征,生成与音频同步的面部动画。
2. 单独通过面部标志生成肖像视频
- 功能描述:EchoMimic 可以仅通过面部关键点(如眼睛、嘴巴等位置的标志)来生成肖像视频。这种方法通过跟踪和使用面部标志的位置变化来生成动画。
3. 结合音频和选定的面部标志生成肖像视频
- 功能描述:EchoMimic 的核心功能是将音频和面部标志结合在一起进行训练和生成。这种方法通过同时考虑音频信号和面部标志的位置变化,生成更自然、更逼真的肖像动画。
4. 多语言和多风格支持
- 功能描述:EchoMimic 支持不同语言的音频输入,并能够根据不同语言的特点生成相应的肖像动画。此外,它还可以处理不同风格的音频,如普通话、英语和歌唱等。
-
音频驱动英语
- 音频驱动唱歌