在构建人工智能驱动的应用程序时,提示词的质量对结果有重大影响。然而,编写高质量的提示词具有挑战性,需要深入了解应用程序的需求和对大型语言模型的专业知识。为了加速开发并改进结果,Anthropic简化了这一过程,使用户更容易生成高质量的提示词。
现在,用户可以在Anthropic控制台中生成、测试和评估提示词。

生成提示
- 目的:帮助开发者创建有效的提示词,以指导AI模型生成所需的响应。
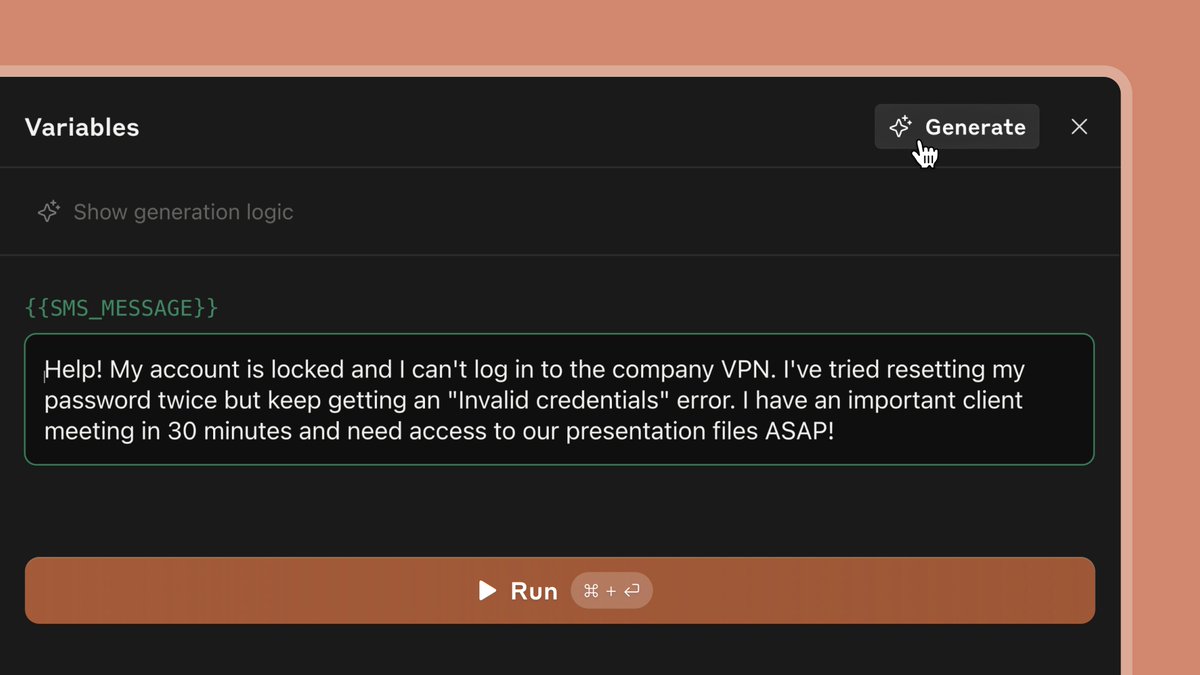
- 功能:通过描述任务(例如“分类入站客户支持请求”),控制台内置的提示词生成器会利用Claude 3.5 Sonnet来自动生成高质量的提示词。
编写一个好的提示可以像向Claude描述任务一样简单。控制台提供了一个内置提示生成器,由Claude 3.5 Sonnet驱动。您只需描述任务(例如,“分类处理入境客户支持请求”),Claude就能为您生成高质量的提示。

您可以使用Claude的新测试用例生成功能为提示生成输入变量,例如一个入境的客户支持消息,然后运行提示以查看Claude的响应。您也可以手动输入测试用例。

生成测试套件
- 目的:在提示词部署到生产环境之前,通过各种真实世界的输入来测试提示词的质量和效果。
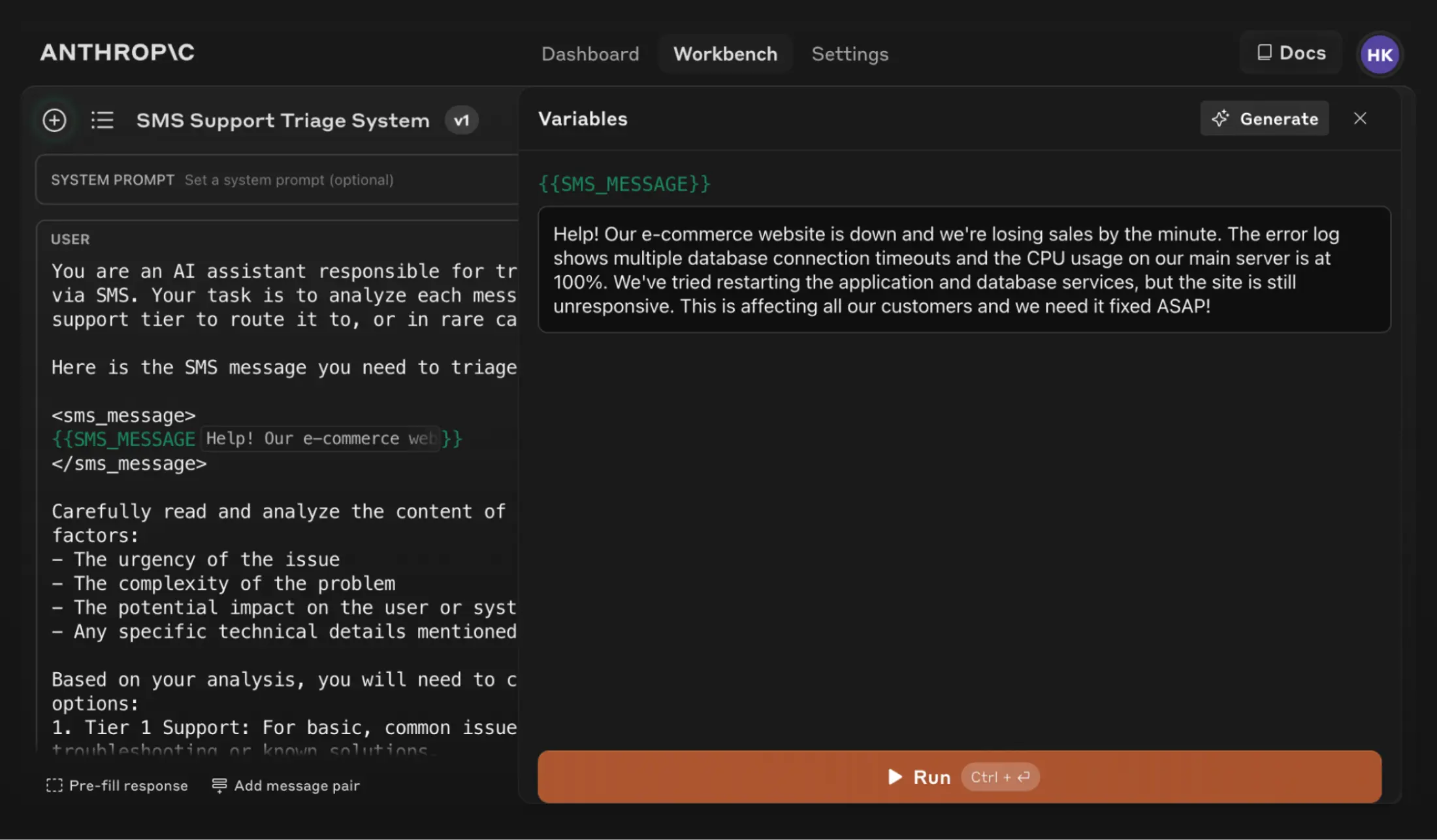
- 功能:用户可以自动生成或手动添加测试用例(例如客户支持消息),并运行这些用例以查看Claude的响应。
通过对一系列真实世界输入进行测试,您可以在将提示部署到生产环境之前,对其质量建立信心。使用新的评估功能,您可以直接在控制台中完成这一操作,而无需手动管理电子表格或代码中的测试。
您可以手动添加或从CSV导入新测试用例,也可以使用“生成测试用例”功能让Claude自动生成测试用例。根据需要修改您的测试用例,然后一键运行所有测试用例。查看并调整Claude对每个变量生成需求的理解,以便更精细地控制Claude生成的测试用例。
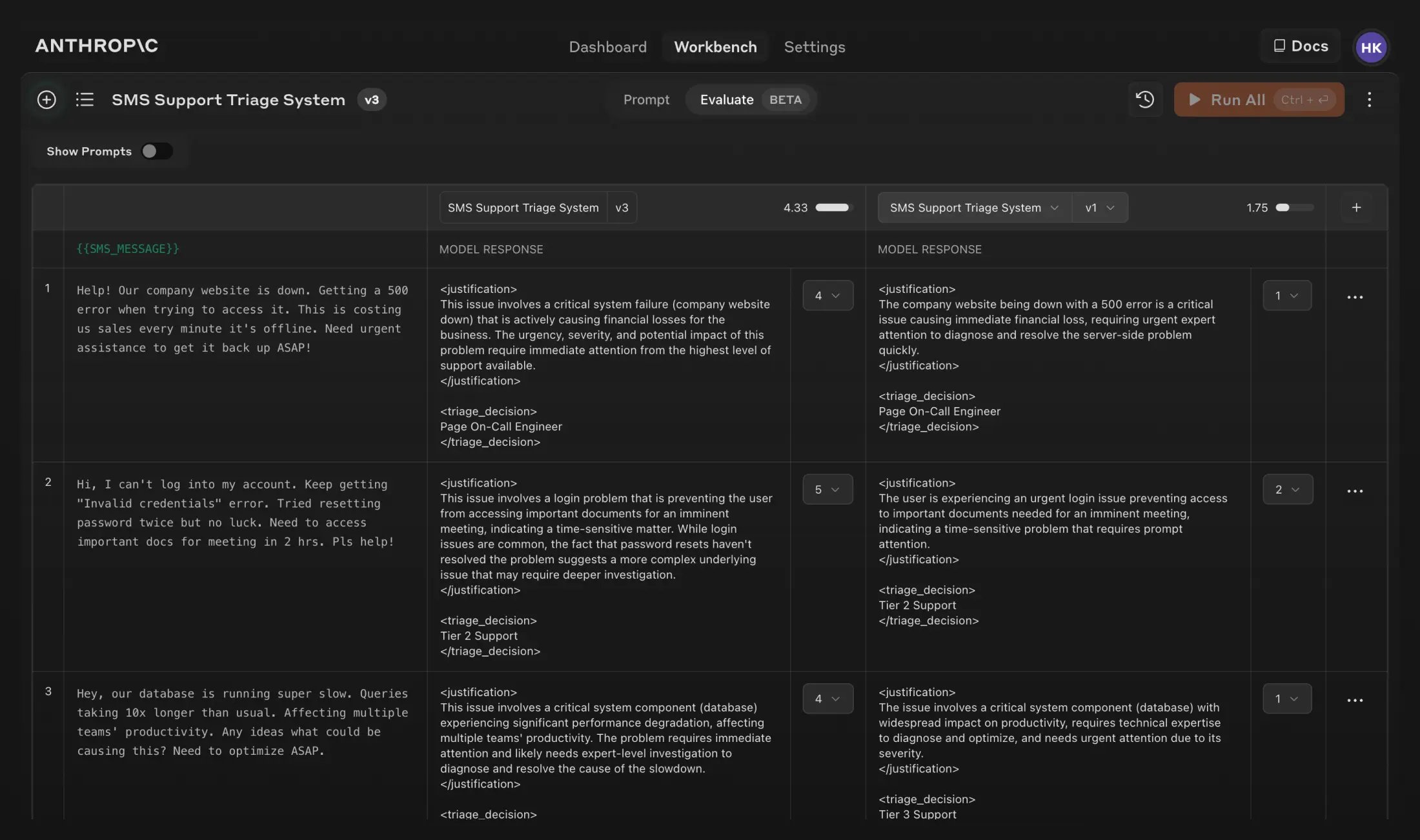

评估模型响应并迭代提示
- 目的:快速改进提示词和AI模型的性能。新的“评估”选项卡使您能够自动创建测试用例,以评估您的提示与真实世界输入的匹配情况。 根据需要修改您的测试用例,然后一键运行所有测试用例。
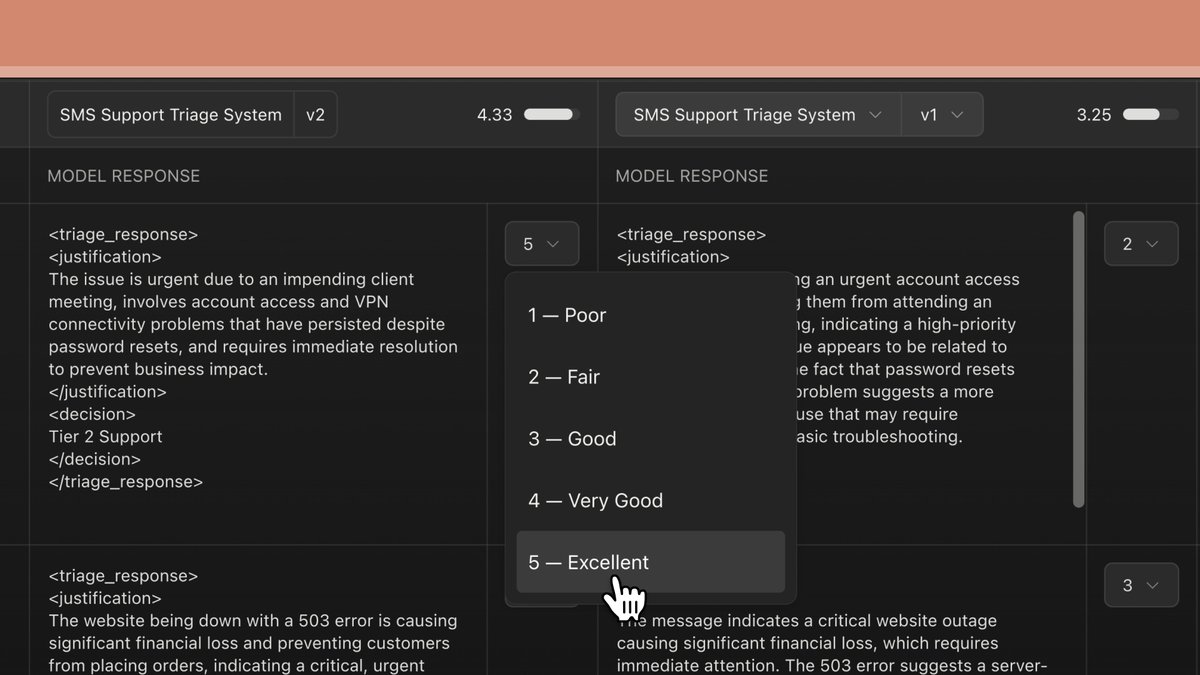
- 功能:用户可以创建提示词的新版本,重新运行测试用例,快速迭代和改进结果。新增的功能允许对比多个提示词输出,并由专家对响应质量进行评分,以进一步改进提示词质量。
- 输出结果比较和评分:用户现在可以并排比较两个或多个提示的输出结果。通过这个功能,主题专家可以在5分制上对不同版本的提示响应进行评分,从而选择最佳提示。