FunAudioLLM 是阿里巴巴开发的一组语音处理模型,旨在改善人类与大语言模型之间的语音交互。它由两个主要模型构成:SenseVoice 和 CosyVoice。
- SenseVoice:语音识别模型,这个模型可以识别多种语言的语音,识别说话人的情感,检测音频中的特殊事件(比如音乐、笑声等)。它可以快速而准确地转录语音内容。
- CosyVoice:语音生成模式,这个模型主要生成自然且情感丰富的语音。它可以模仿不同的说话人,甚至可以用几秒钟的音频样本来克隆一个人的声音。
通过 SenseVoice 和 CosyVoice 的结合,FunAudioLLM 提供了全面的语音理解和生成功能,使得人与大语言模型之间的语音交互更加自然和丰富。
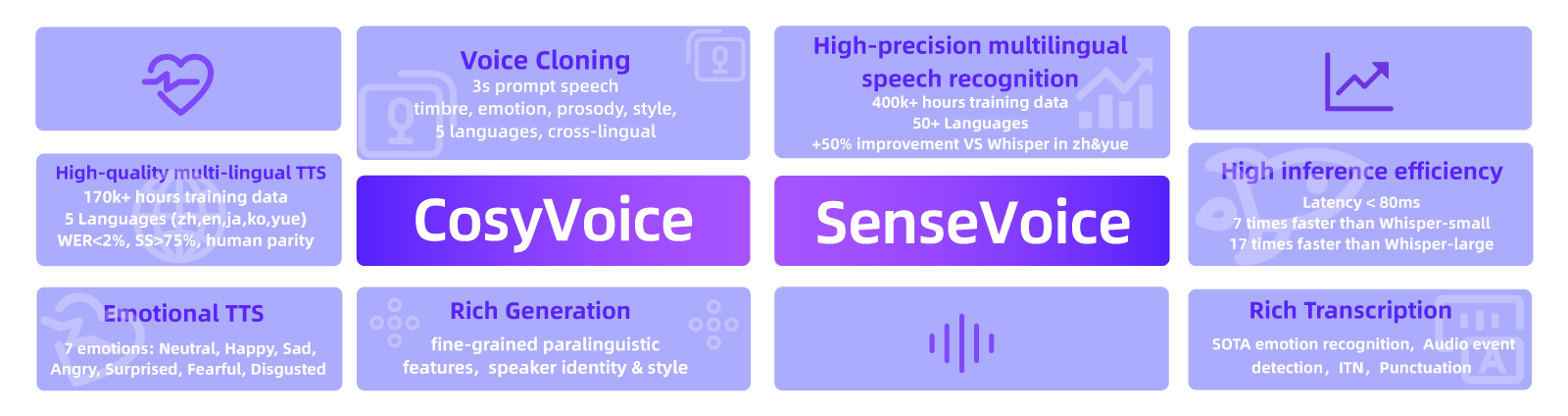

SenseVoice 主要专注于多语言语音识别、情感识别和音频事件检测,提供高精度、低延迟的语音处理能力。CosyVoice 则侧重于自然语音生成和控制,支持多种语言、音色和说话风格的生成,能够实现零样本学习和细粒度的语音控制。这两者结合,使得 FunAudioLLM 能够在多种应用场景下提供卓越的语音交互体验。
SenseVoice 主要功能
- 多语言语音识别
- SenseVoice-Small:支持中文、英语、粤语、日语和韩语五种语言,采用非自回归端到端架构,识别延迟极低,比 Whisper-small 快5倍,比 Whisper-large 快15倍。
- SenseVoice-Large:支持超过50种语言的高精度语音识别。
- 情感识别
- 识别语音中的情感,如快乐、悲伤、愤怒等情感,通过检测语音的音调、节奏和语调变化来实现。
- 音频事件检测
- 检测语音中的特殊事件,如音乐、笑声、掌声等,并能预测事件的开始和结束时间。
- SenseVoice-Small 能够检测各种人机交互事件,如背景音乐、掌声、笑声、哭声、咳嗽和打喷嚏等。
- 语言识别
- 能够识别说话者所使用的语言,确保语音识别的准确性和上下文理解。
- 逆文本规范化(Inverse Text Normalization, ITN)
- 提供带标点和格式化的转录结果,提高转录文本的可读性和准确性。
主要特点
- 多语言语音识别:训练数据超过40万小时,识别性能优于 Whisper 模型。
- 高效推理:SenseVoice-Small 模型采用非自回归端到端框架,推理延迟极低,处理10秒音频只需70毫秒,速度比 Whisper-Large 快15倍。
- 情感识别:在多个测试数据集上,达到了当前最佳情感识别模型的效果。
- 事件检测:支持多种常见的音频事件检测。
- 便捷的微调:提供便捷的微调脚本和策略,用户可以根据业务场景轻松解决长尾样本问题。
- 服务部署:提供服务部署管道,支持多并发请求,客户端语言包括 Python、C++、HTML、Java 和 C# 等
CosyVoice 主要功能
- 语音生成
- 支持多语言语音生成,包括中文、英语、粤语、日语和韩语。
- 能够生成自然且情感丰富的语音,支持不同的说话风格和情感表达。
- 多样化的语音控制
- 音色控制:可以精确控制生成语音的音色,使其与特定说话者的声音匹配。
- 说话风格控制:通过文本指令控制语音的说话风格,如情感、语速、音高等。
- 零样本学习
- 通过仅几秒钟的音频样本进行声音克隆,无需额外训练数据。
- 支持跨语言的声音克隆,实现用一种语言的声音说另一种语言的话。
- 细粒度的副语言特征控制
- 支持插入笑声、呼吸声、语气词等细微的语音特征,使生成的语音更加自然和生动。
- 文本指令控制:可以通过文本指令精确控制说话人的身份、情感和说话风格。
- 多角色对话
- 能够生成多角色的对话语音,适用于互动播客、情感聊天等场景。
FunAudioLLM 的应用
1. 语音到语音翻译 (Speech-to-Speech Translation)
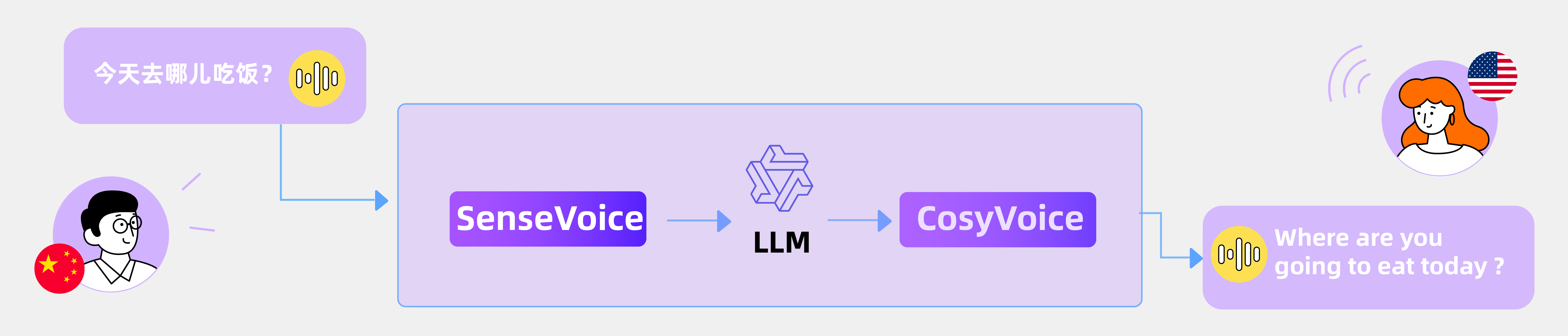

FunAudioLLM 可以实现高质量的语音到语音翻译。具体过程如下: