

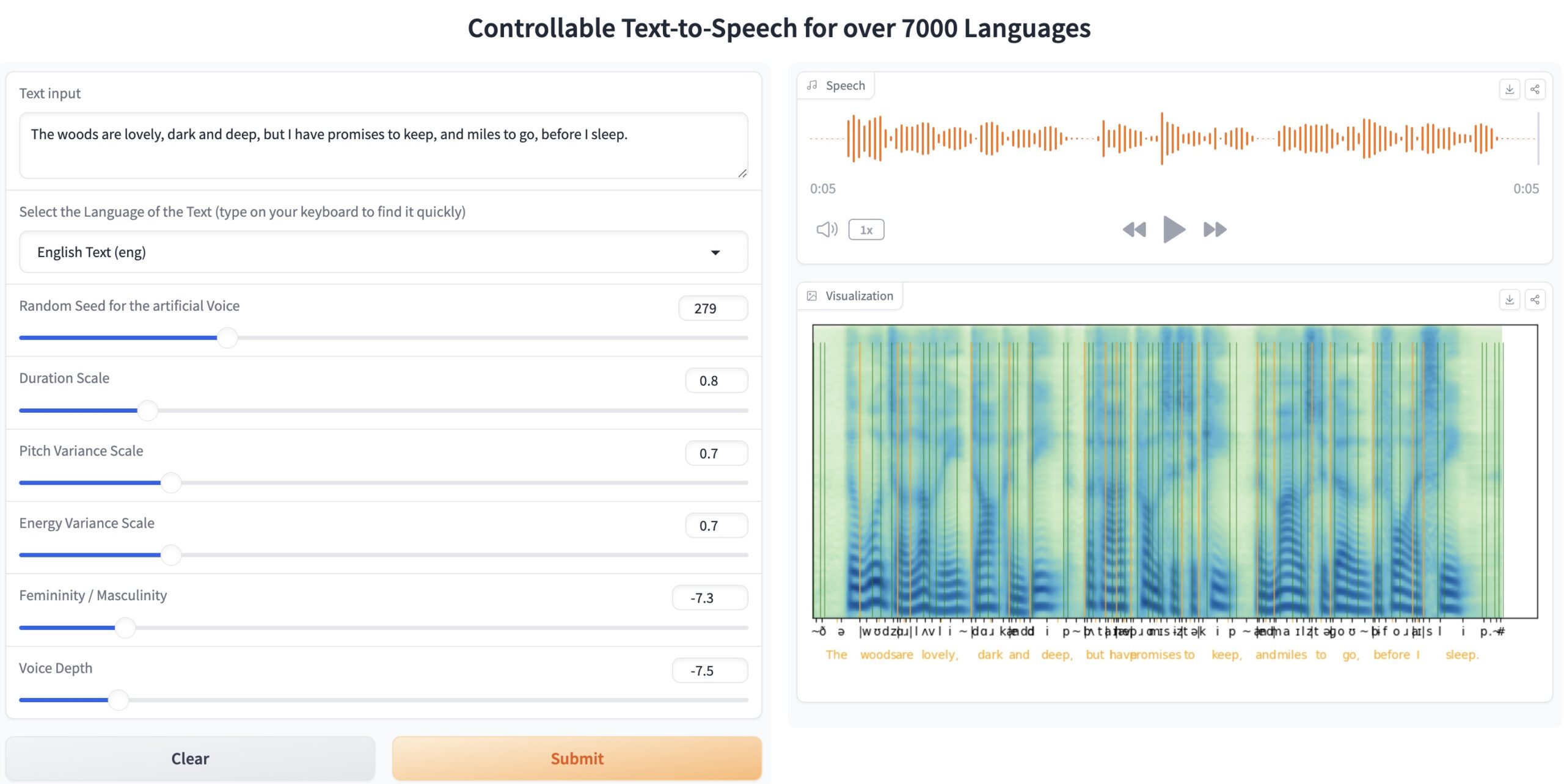
斯图加特大学自然语言处理研究所(IMS)开发了一个超全文本转语音模型ToucanTTS。ToucanTTS专为教学、训练和使用最先进的语音合成模型而设计。 是目前最多语言的 TTS 模型,支持超过7000种语言的语音合成,具备多说话人语音合成功能,能够模拟多种说话人的节奏、重音和语调。
ToucanTTS 提供了多种应用的交互演示,包括语音设计、风格克隆、多语言语音合成和人工编辑诗歌朗读,展示了其多功能性和强大性能。
该工具包基于 FastSpeech 2 架构,包含一些改进,如基于 PortaSpeech 的正则流 PostNet,确保了自然高质量的语音合成。ToucanTTS 还包含一个使用连接时序分类(CTC)和声谱图重建训练的对齐器,用于多种用途。
主要功能
- 多语言支持:支持几乎所有的 ISO-639-3 标准语言,这意味着它理论上可以支持超过 7000 种语言。是目前支持语言种类最多的 TTS 模型。这使得它在全球范围内具有广泛的适用性,满足不同语言背景用户的需求。通过内置的语言嵌入模型,可以在多个语言之间无缝切换,实现多语言合成。
- 多说话人语音合成:该工具包支持多说话人语音合成功能,可以模拟不同说话人的节奏、重音和语调。这对于需要风格多样性和语音自定义的应用非常有用。
- 可控语音合成:该工具包允许用户控制语音的多个参数,包括音调、语速、情感等。通过这种控制,可以生成具有不同情感或风格的语音输出。
- 高质量语音生成:利用 PyTorch 框架,IMS-Toucan 采用最先进的深度学习技术,保证语音生成的高保真度和自然性。模型支持端到端的训练和推理,能够处理复杂的语音合成任务。
- 人工编辑功能:ToucanTTS 包含人类在环(Human-in-the-loop)的编辑功能,特别适用于文学研究和诗歌朗读任务。用户可以根据自己的需求和喜好自定义合成的语音。
- 自包含对齐器:该工具包还包含一个使用连接时序分类(CTC)和声谱图重建训练的对齐器,适用于多种用途。这提高了语音合成的精度和质量。
- 数据预处理工具:提供了一整套数据预处理工具,包括文本清理和特征提取,简化了训练数据的准备工作。

GitHub:https://github.com/DigitalPhonetics/IMS-Toucan
在线演示:https://huggingface.co/spaces/Flux9665/MassivelyMultilingualTTS