Florence-2 是一个由微软开发的新的视觉模型,主要用来处理各种图像任务。它可以通过简单的文字提示完成任务,比如描述图片内容、识别和定位图片中的物体,以及分割图片中的不同区域。
Florence-2 解决了现有大视觉模型在处理多样化任务时的局限性,提供了统一的解决方案,能够高效地处理各种复杂的视觉任务。
它不仅能描述图片的内容,还能识别图片中的物体,并指出这些物体的位置。比如,如果你给它一张公园里的图片,它可以告诉你图片里有一个穿蓝衣服的女孩在玩耍,旁边还有一只狗。
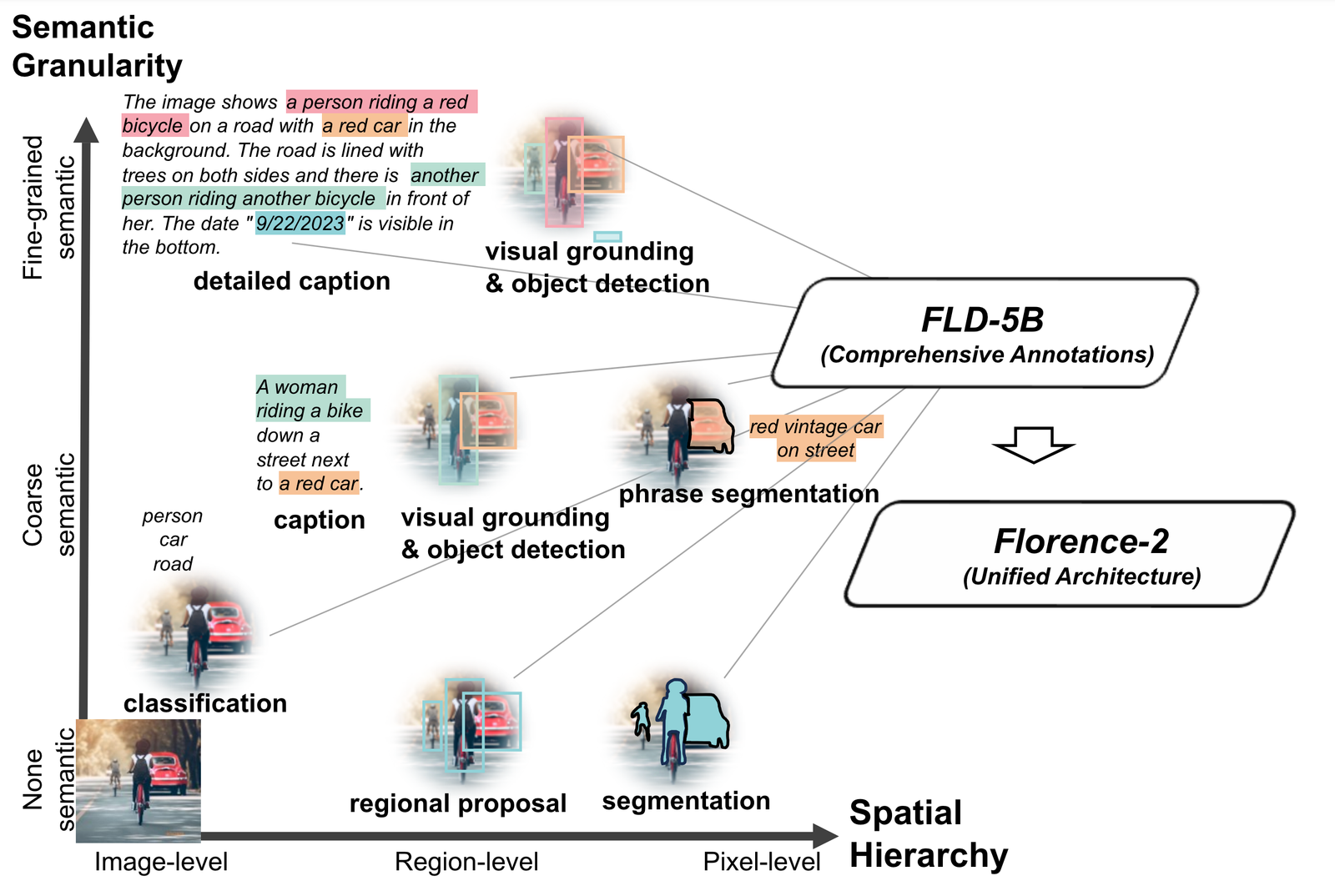

Florence-2 能够执行超过 10 种不同的视觉任务,包括图像字幕生成、对象检测、图像区域关联和分割等。这种广泛的任务能力证明了其在多任务处理上的高效性和实用性。
- 图像描述:自动生成对图像内容的文字描述。
- 目标检测:识别和定位图像中的不同物体。
- 视觉定位:在图像中找到与文本描述相对应的具体区域。
- 图像分割:将图像划分为不同的区域,识别每个区域的内容。
为了让 Florence-2 能处理这些任务,研究人员开发了一个巨大的数据集,包含了5.4亿个详细的图片注释。通过学习这个数据集,Florence-2 学会了如何理解和处理各种图像任务。