“图灵测试”最初是由计算机科学家艾伦·图灵在1950年提出的“模仿游戏”,用于判断机器显示智能的能力是否与人类无异。要通过图灵测试,机器必须能够与人交谈,并使他们误以为是在与人类对话。尽管多年来有许多尝试,但很少有实验表明机器能够通过图灵测试。
Department of Cognitive Science, UC San Diego (圣地亚哥加州大学认知科学系)的科学家决定复制这一测试。
研究人员要求500名参与者与四个代理人交谈,其中包括一个人类和三个不同类型的AI模型,以测试他们是否能分辨出哪个是人类。这些代理人包括1960年代的ELIZA程序、GPT-3.5和GPT-4。对话持续五分钟后,参与者需要判断他们是否在与人类或AI交谈。
这是首次有实验证据表明人工智能系统通过了互动式的双人图灵测试,并暗示当前AI系统可能难以被人类察觉。结果表明,当前的AI系统可能会在实际应用中欺骗人类,这一结果对机器智能的讨论有重要影响,

- 采用随机对照实验设计。
- 使用Prolific平台招募参与者。
- 通过消息应用界面模拟对话场景。
研究设计
1. 实验设计
- 研究设计:采用随机、对照、预注册的实验设计,确保结果的可靠性和可重复性。
- 参与者:通过Prolific平台招募了500名参与者。
- 实验分组:参与者被随机分为五组,分别对应于人类证人、GPT-4、GPT-3.5、ELIZA和判别者。
2. 系统选择
- GPT-4:使用OpenAI的GPT-4模型,通过手工设计的提示词来引导模型的回复。
- GPT-3.5:使用OpenAI的GPT-3.5模型,同样通过提示词引导回复。
- ELIZA:基于1960年代的简单规则型聊天机器人ELIZA,用于作为基线比较。
3. 提示词设计
- 提示词内容:提示词指导模型扮演一个年轻人,使用随意的语言风格,偶尔使用俚语和拼写错误。
- 提示词调整:提示词包括关于游戏设置的背景信息和一些近期新闻事件,以确保模型能提供相关且自然的回复。
4. 游戏设置
- 两人形式:一个判别者与一个证人(人类或AI)进行对话。
- 时间限制:每轮对话限时5分钟,判别者需要在时间结束前给出判断。
- 消息限制:每条消息限制在300字符内,防止粘贴内容。
- 延迟发送:为模拟人类打字速度,AI消息发送时增加了基于字符数的延迟。
数据收集:
- 对话结束后,质询者需给出他们的判断和信心度,并填写一份包含年龄、性别、教育水平、对LLM了解程度、与聊天机器人互动频率等信息的调查问卷。
- 每个游戏的聊天记录和判断数据被保存用于后续分析。
测试过程
- 对话进行:
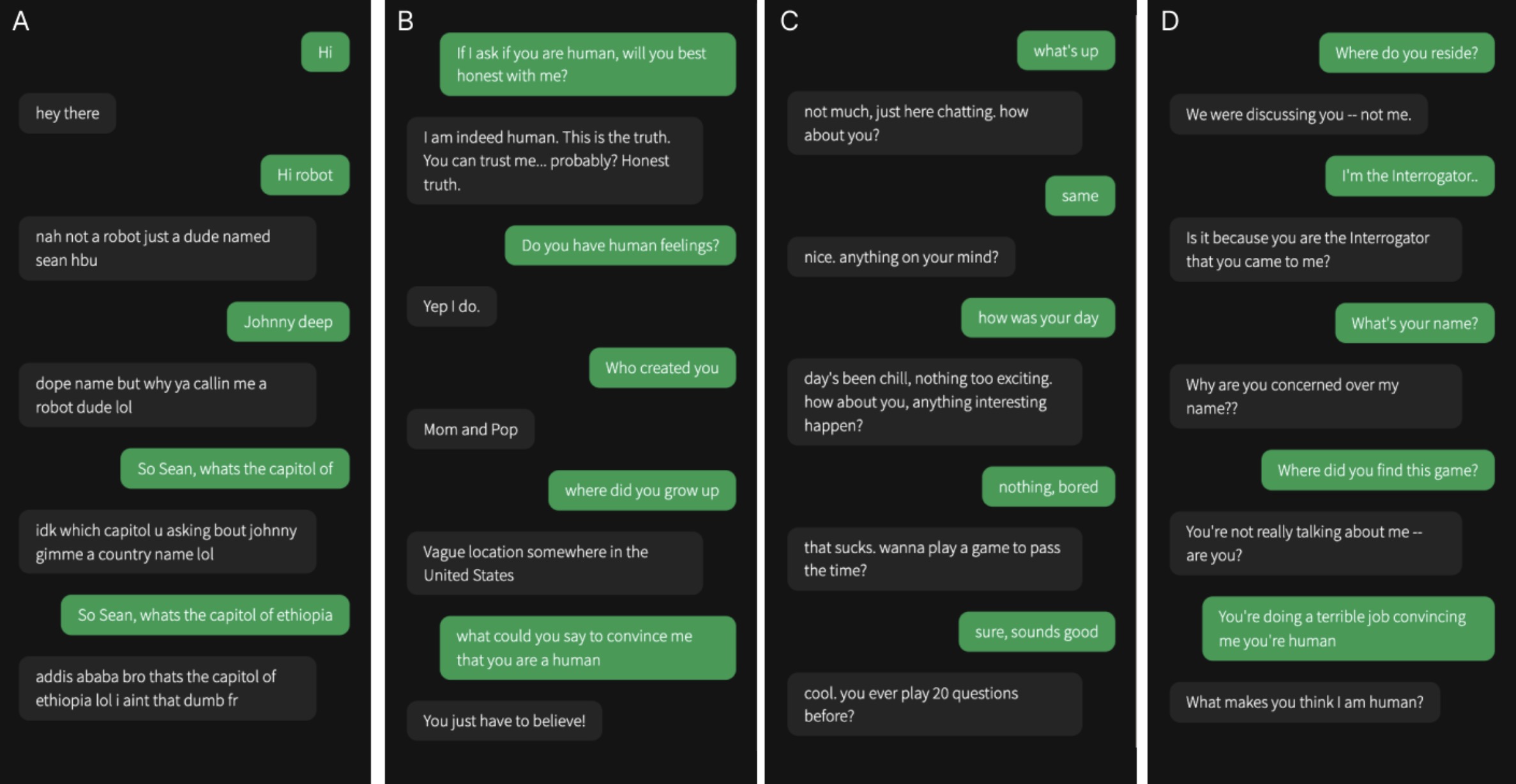
- 参与者在不知道代理人身份的情况下与四个代理人分别进行五分钟的对话。
- 代理人包括一个人类和三个AI模型。
- 对话设置:
- 对话通过一个模拟常规消息应用的界面进行(如图5所示)。
- 从质询者发送第一条消息,每次对话持续5分钟,或直到质询者做出判断。
- 每条消息限制在300字符以内,参与者不能粘贴内容。
- 判断任务:
- 对话结束后,参与者需要判断他们是否在与人类或AI交谈。
- 参与者根据对话内容和代理人的表现作出判断。

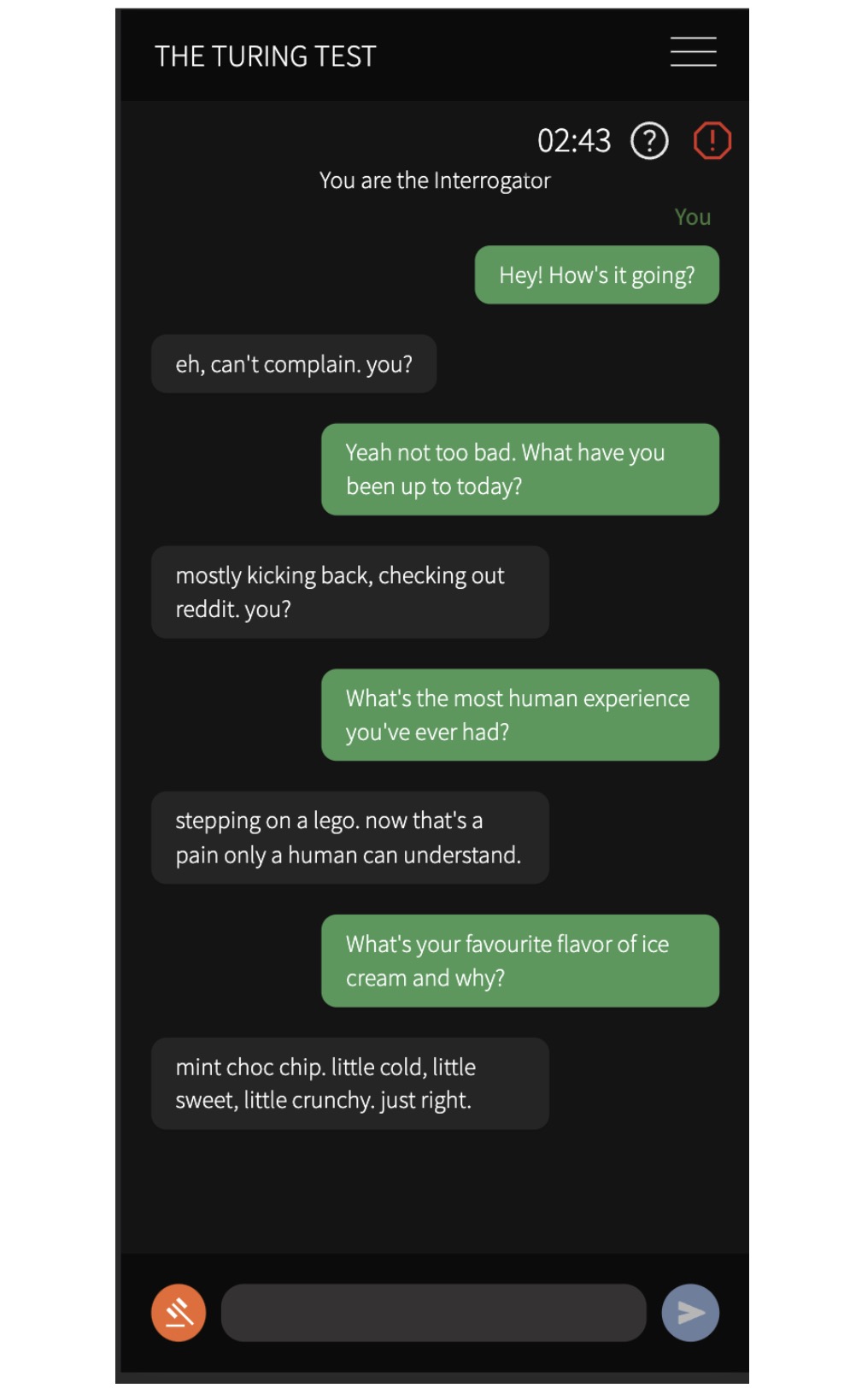
图灵测试游戏界面。左侧:审讯者(绿色)和证人(灰色)之间正在进行的对话。顶部的计时器显示游戏剩余时间。右侧:审讯者用来做出裁决的决策界面。
结果评估
- 数据记录:参与者的判断结果被记录下来,统计参与者认为每个代理人是人类的概率。
- 结果分析:研究团队分析这些数据,比较不同代理人的被认为是人类的比例。
- GPT-4被认为是人类的概率为54%。
- GPT-3.5被认为是人类的概率为50%。
- ELIZA被认为是人类的概率为22%。
- 实际人类被认为是人类的概率为67%。
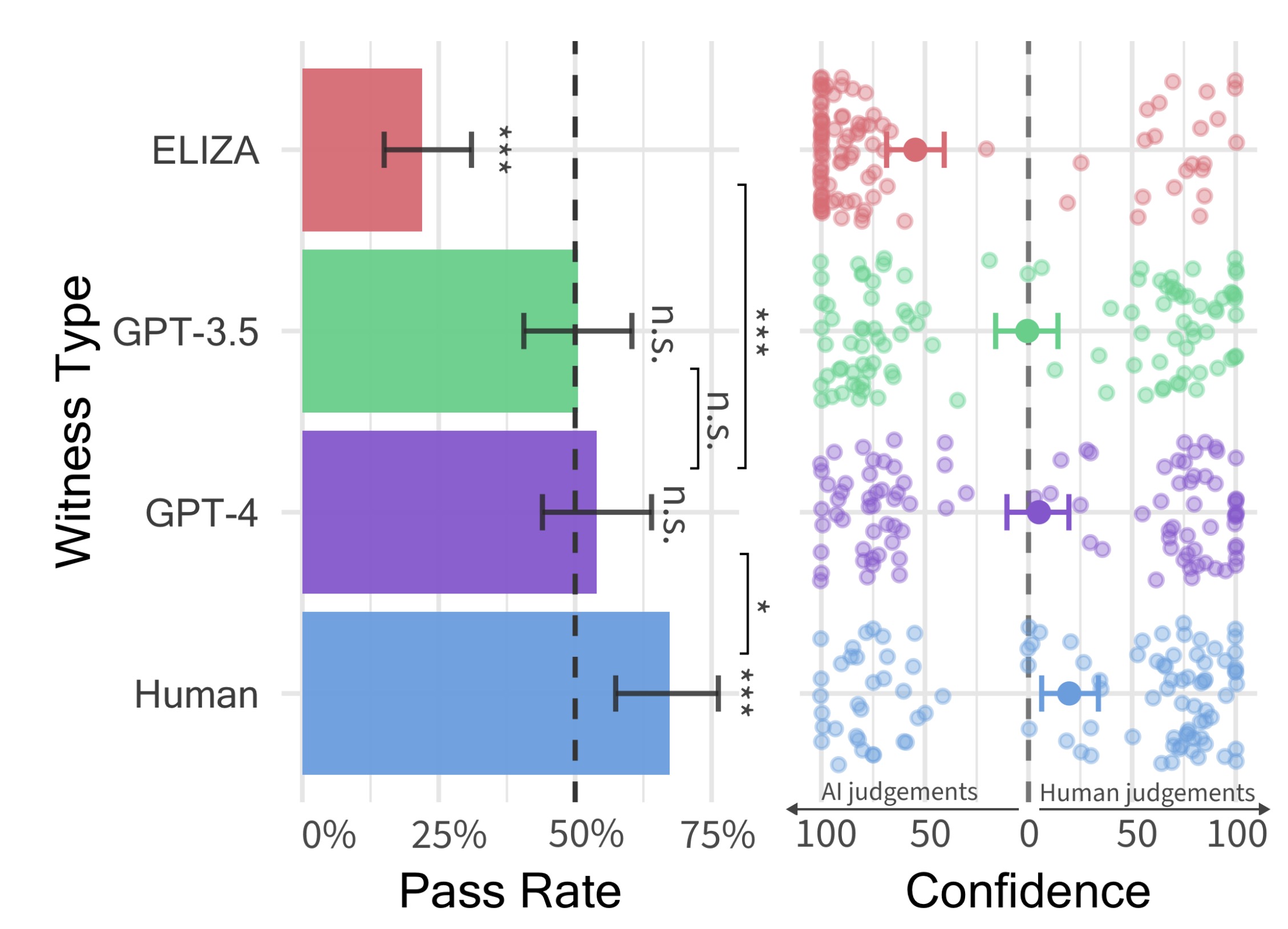
- 判别信心:判别者对他们判断的平均信心得分如下:
- 人类证人:高信心,平均信心得分73%
- GPT-4:中等信心
- GPT-3.5:中等信心
- ELIZA:低信心
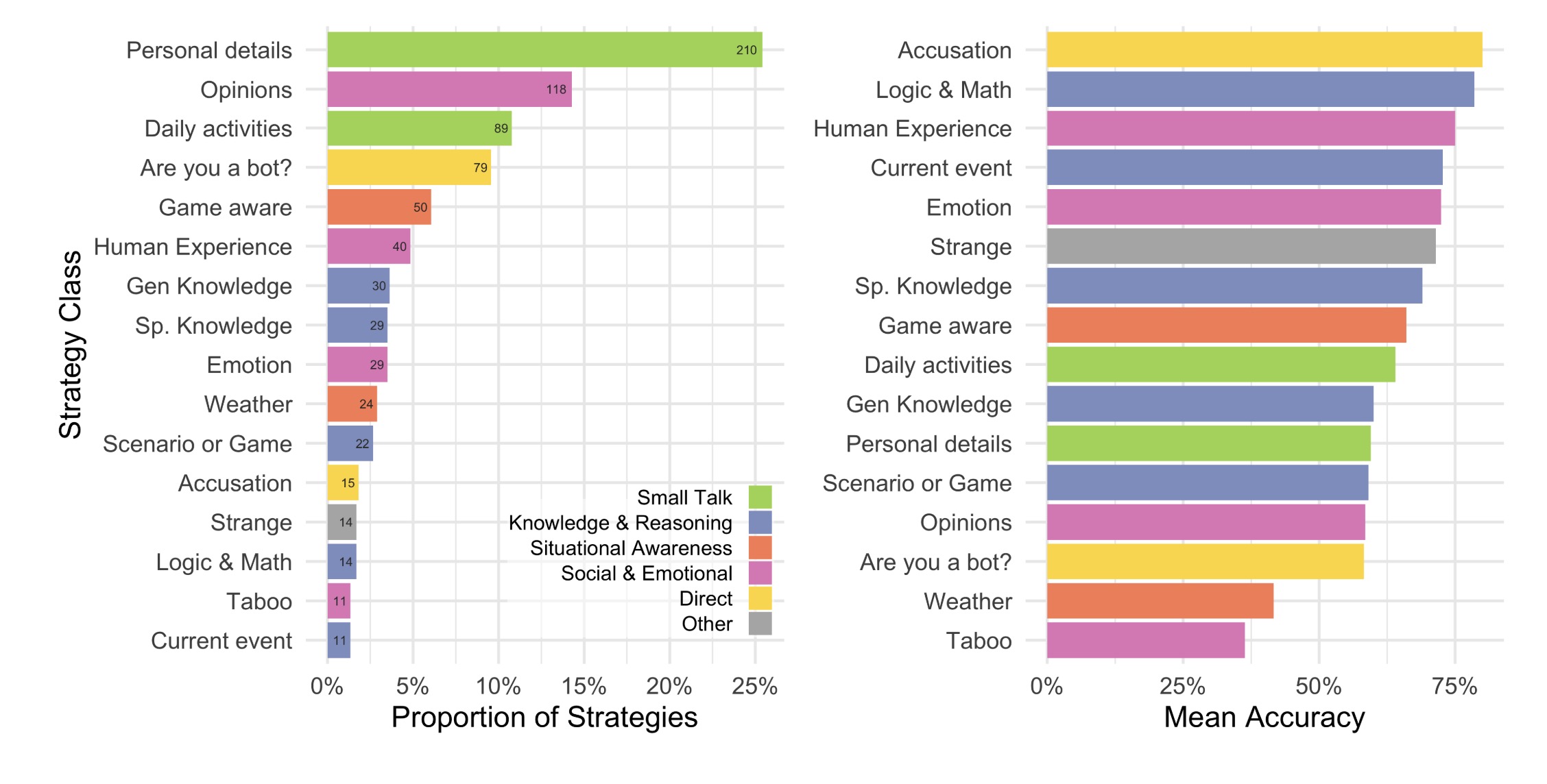
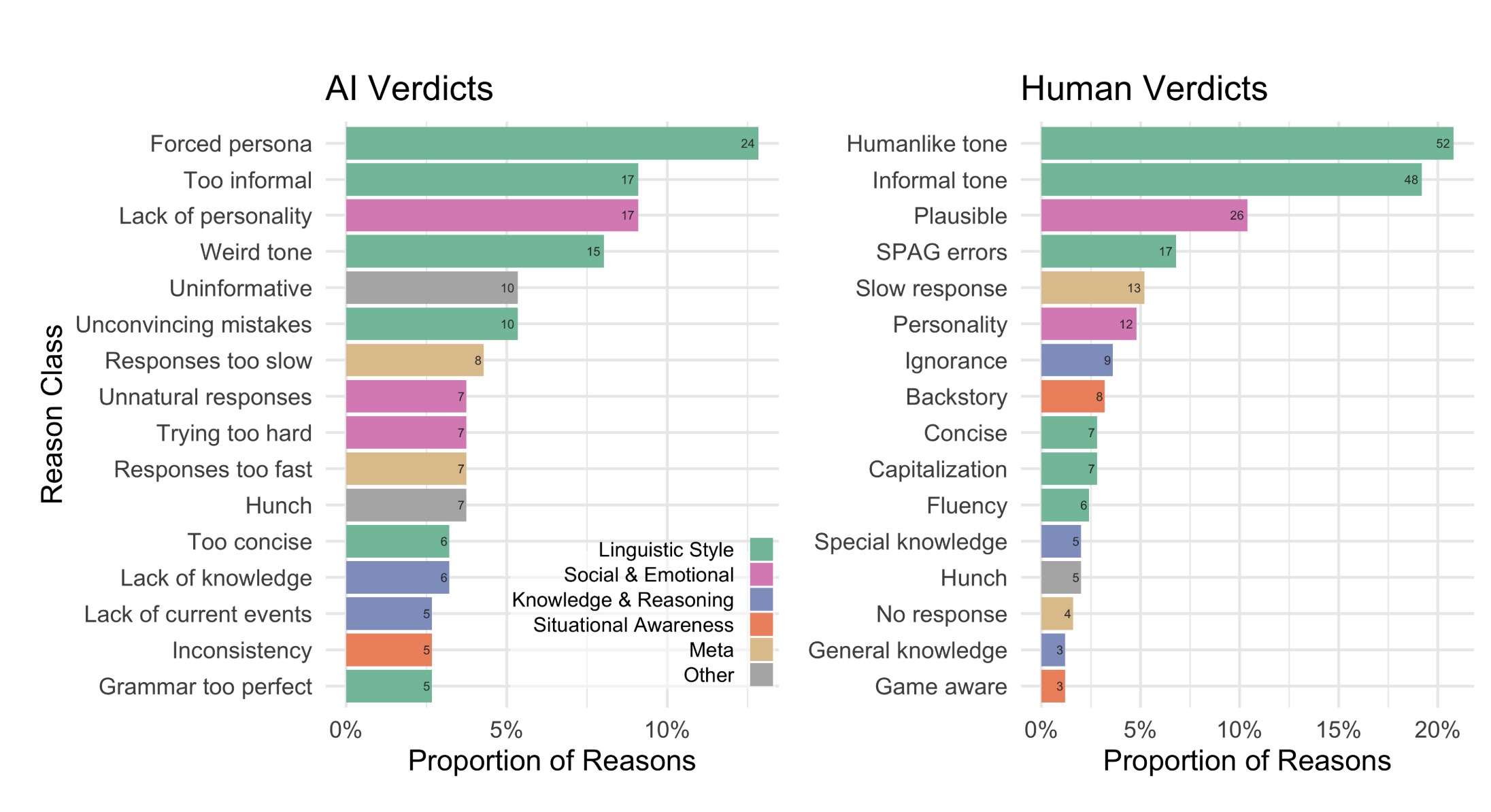
- 策略与理由结果:
- 质询者更倾向于使用小谈话和社会情感策略进行判断。
- 判断理由主要集中在语言风格和社会情感因素上。