
UltraMedical是由清华大学, 华盛顿大学, 南昌大学第一附属医院, 上海交通大学, Frontis.AI共同建高质量的生物医学指令数据集和使用先进的对齐技术训练语言模型,致力于在生物医学领域开发专门通才模型。这些模型不仅在处理特定问题时表现优异,还能在跨领域问题中提供有效的解决方案。
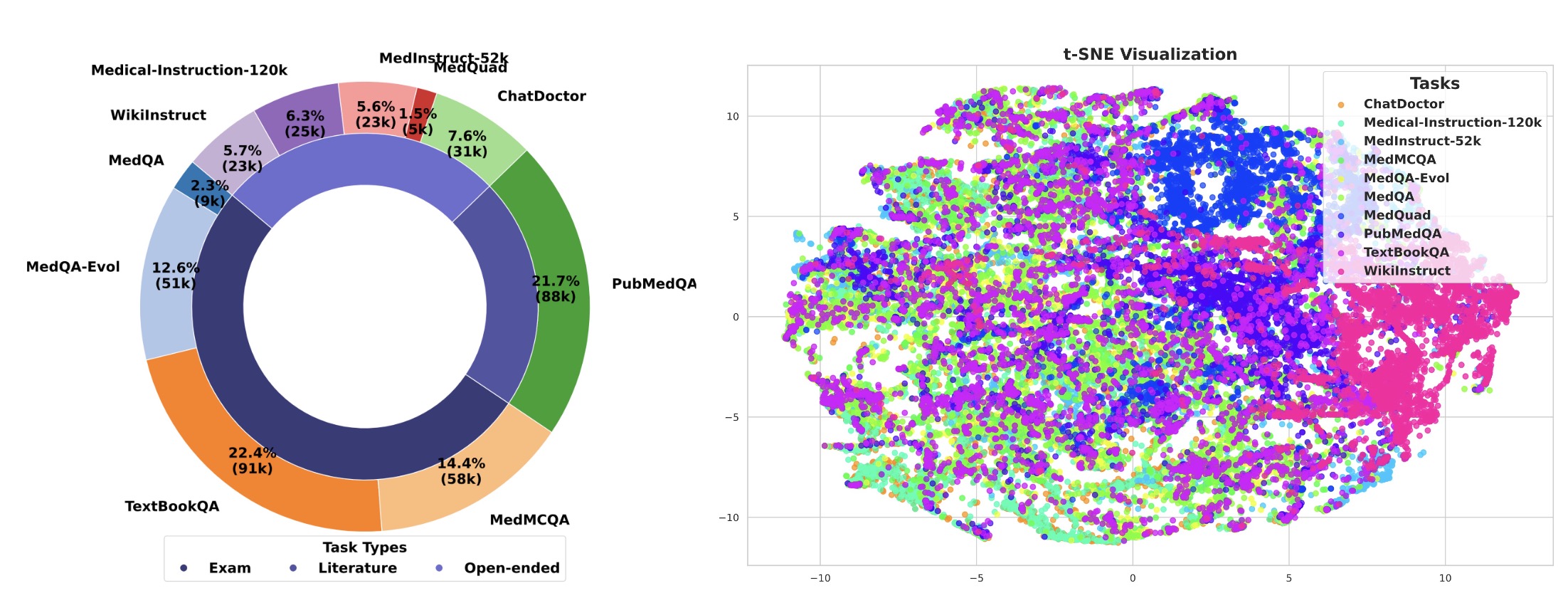
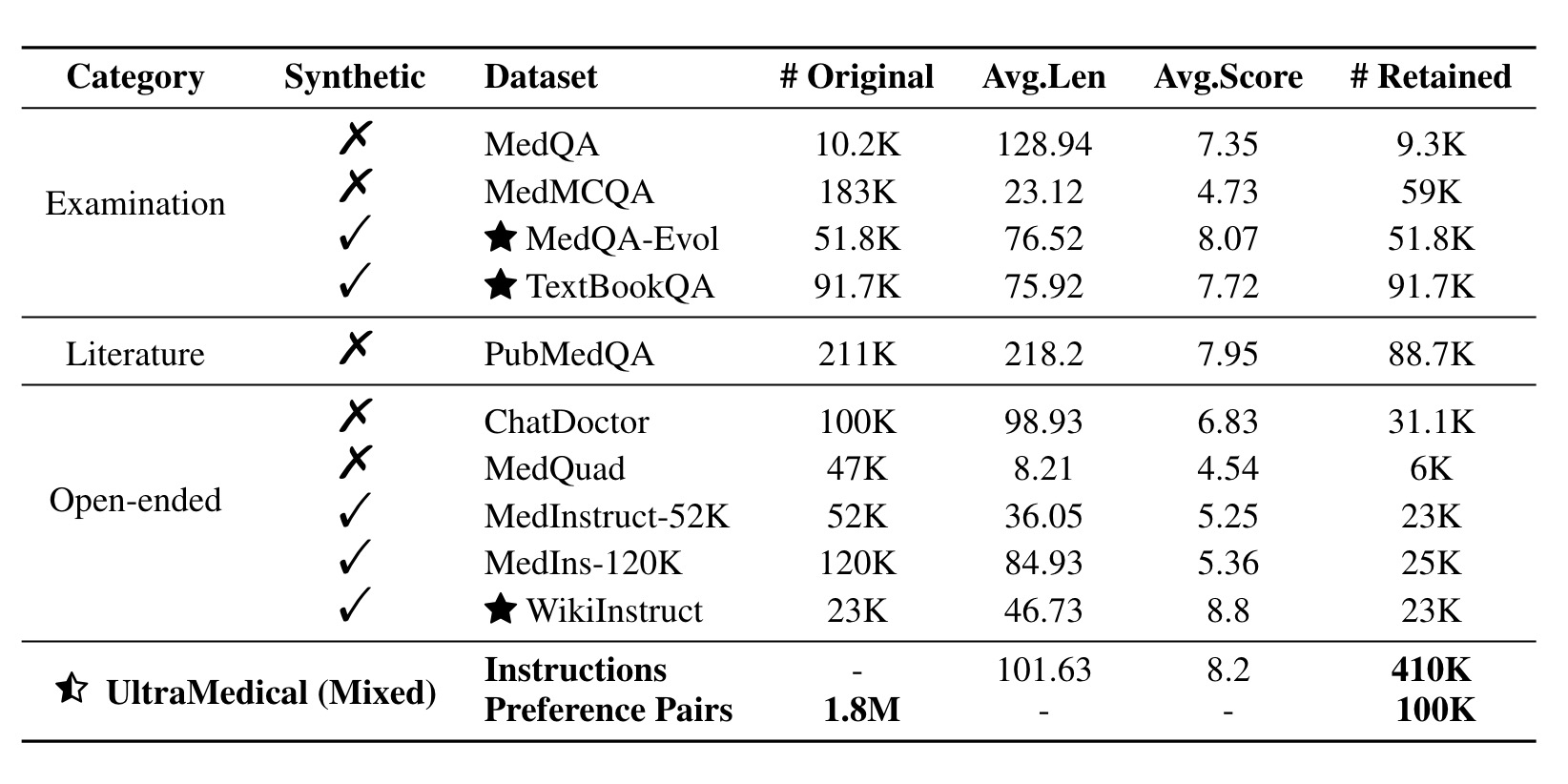
UltraMedical数据集是一个大规模、高质量的生物医学指令集合,包含410,000个合成和手工整理的样本,结合手工和合成的提示,其中约100K条指令带有偏好注释。
 数据集详细信息
数据集详细信息
数据集包含各种医学考试题目、PubMed文献研究、开放式问题等,并通过多种高级LLM进行注释和偏好打分。
- 指令总数:约410K条。
- 偏好对:约1.8M对偏好对,用于奖励建模和偏好学习。
数据集构成
1. 数据集组成原则:
- 多样性原则:
- 数据集包括医学考试题、文献基础问题和开放式指令(如临床问题、研究问题等)。
- 数据来源包括公开的医学考试、文献、临床问题和开放式指令。
- 三个合成数据集用于增强数据集,包括从MedQA进化而来的MedQA-Evol、从医学教科书中提取的多选题TextBookQA、从维基百科扩展的生物医学概念和指令WikiInstruct。
- 复杂性原则:
- 通过两种方法提高指令的复杂性:前处理方法和后处理方法。
- 使用gpt-3.5-turbo对每个指令进行评分,范围从1到10,其中1表示容易回答,10表示对ChatGPT具有挑战性。
- 对于合成数据集,使用两步自我进化过程,并根据模型派生的分数进一步筛选指令。
 2. 数据注释:
2. 数据注释:
- 完成注释:
- 使用gpt-4-turbo对各种指令进行回答,并验证答案的准确性。
- 对于错误的答案,使用动态检索的少量CoT(思维链)示例进行进一步的注释和验证。
- 偏好注释:
- 采样多个高级模型的完成结果进行偏好注释,包括开放源代码模型(如Llama-3-8B/70B, Qwen1.5-72B等)和专有模型(如gpt-3.5-turbo和gpt-4-turbo)。
- 使用GPT-4对候选答案进行评分和排名,并将评分最高的答案作为“选择”答案,评分较低的答案作为“拒绝”答案。
- 医学奖励基准:
- 从所有偏好样本中随机选择1000个样本进行基准测试,并根据GPT-4的评分将样本分类为“容易”、“困难”和“长度”集。
- 由生物医学临床医生、研究生和研究人员修正偏好对,确保偏好的准确性。
3. 数据集构建方法
- 预先方法:从各种种子指令开始合成新指令,并对这些合成指令进行自我演化。
- 后续方法:使用启发式规则或模型评分筛选出最复杂的指令。对于公共数据集,使用gpt-3.5-turbo分配难度评分(1到10分),确保复杂性。对于合成数据集,结合预先和后续方法进行复杂性增强。
4.详细示例
示例1:
- 指令: 描述心脏病的主要症状。
- 注释:
- 回答1: 心脏病的主要症状包括胸痛、呼吸急促、心悸、恶心和出汗。
- 回答2: 心脏病患者可能会经历胸部不适、疲劳和头晕等症状。
- 选择答案: 回答1
- 拒绝答案: 回答2
示例2:
- 指令: 什么是糖尿病?
- 注释:
- 回答1: 糖尿病是一种由于胰岛素分泌不足或身体对胰岛素的反应不良引起的慢性疾病。
- 回答2: 糖尿病是一种血糖水平异常升高的疾病。
- 选择答案: 回答1
- 拒绝答案: 回答2
基于UltraMedical的Llama-3微调
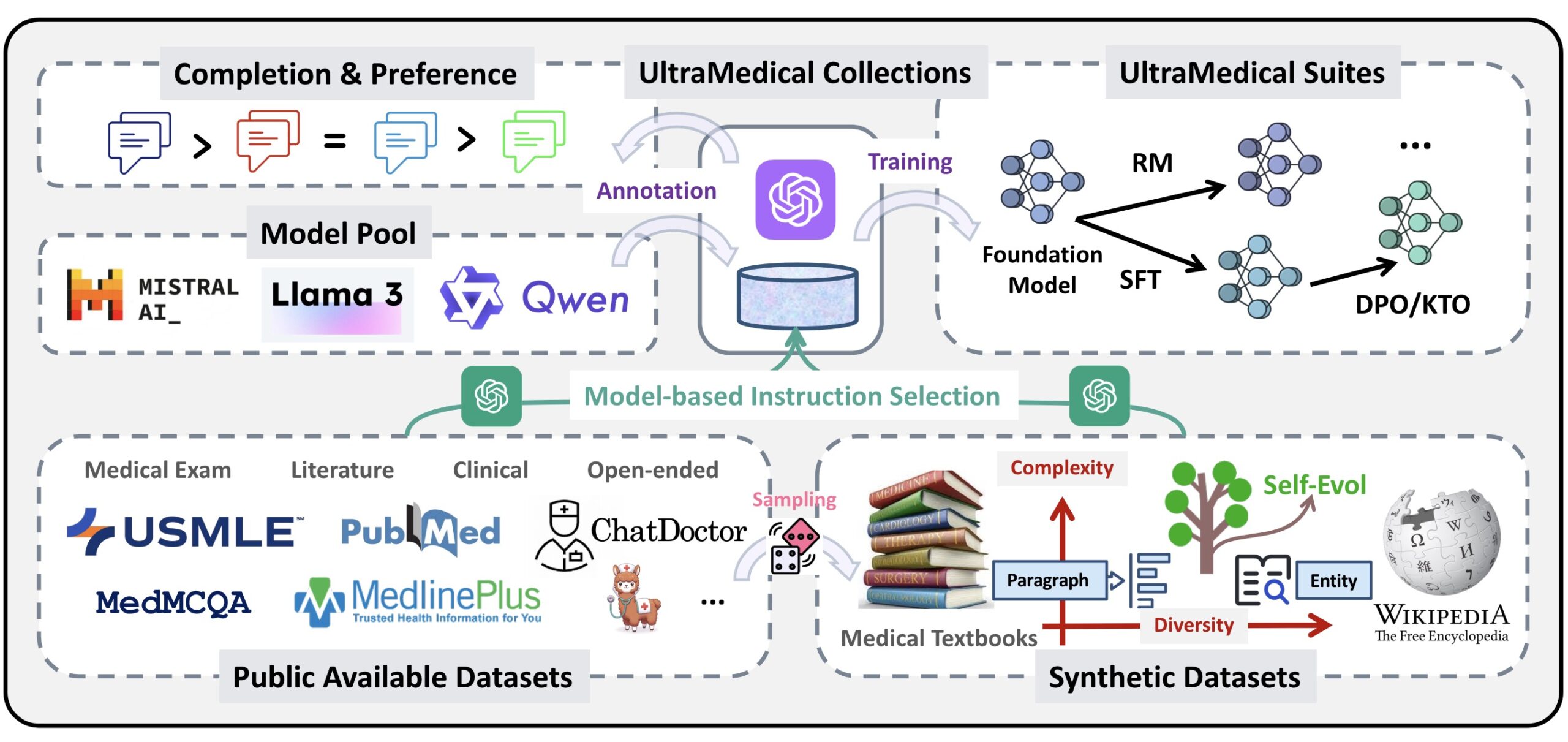 UltraMedical项目在Llama-3系列模型上进行了全面的微调和优化,主要包括监督微调(SFT)、偏好优化(DPO和KTO)以及奖励模型训练和迭代偏好学习。
UltraMedical项目在Llama-3系列模型上进行了全面的微调和优化,主要包括监督微调(SFT)、偏好优化(DPO和KTO)以及奖励模型训练和迭代偏好学习。
- 通过多步优化策略,生成了在多个医疗基准测试中表现出色的专门医疗模型。
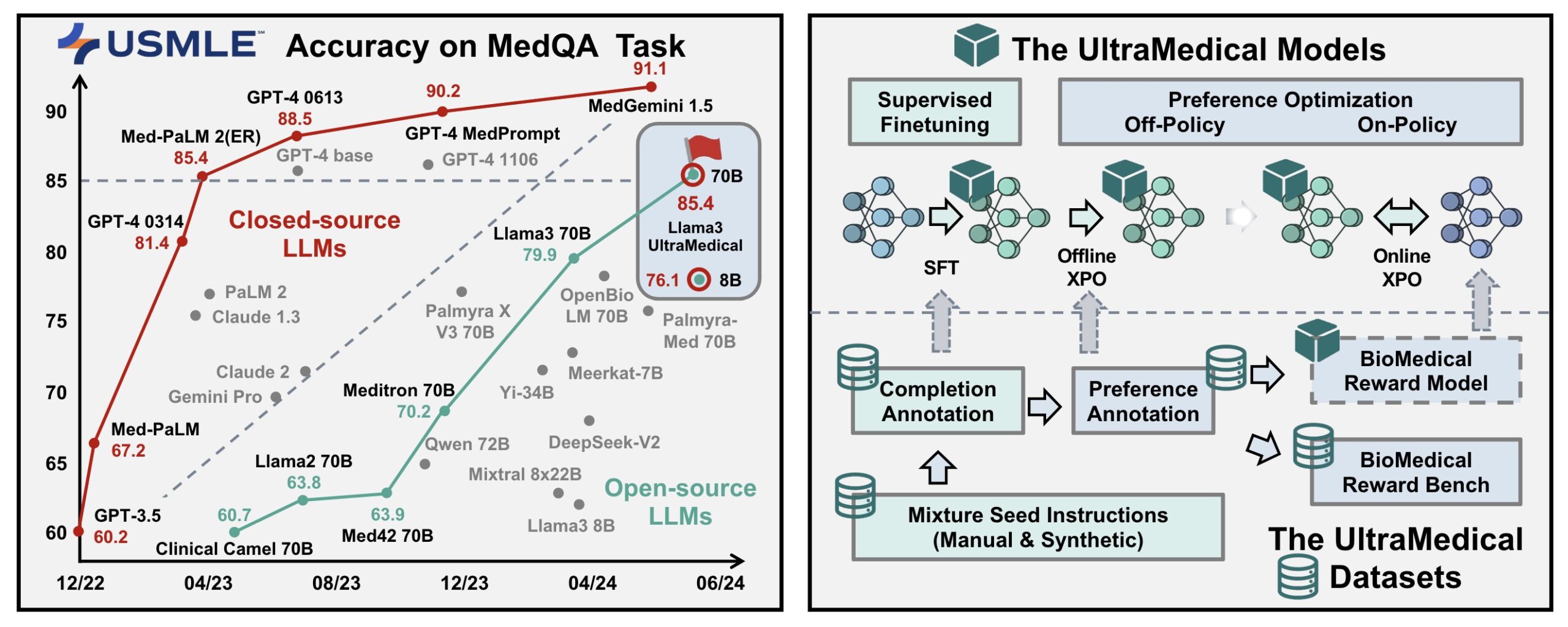
- UltraMedical 8B和70B模型在多个医疗基准上达到了竞争性的结果,特别是UltraMedical 70B模型在MedQA-USMLE测试中取得了86.5的高分。
以下是具体的过程和方法:
1. 监督微调 (Supervised Fine-Tuning, SFT)
过程:
- 基础模型:使用Llama-3 8B和70B基础模型。
- 数据集:利用UltraMedical数据集进行微调,包括410K条医学指令。
- 整合通用数据:为了增强模型的通用指令跟随能力,整合了UltraMedical数据集和通用领域数据集(如UltraChat、ShareGPT、Open-Orca等),共约600K条指令。
方法:
- 使用gpt-4-turbo生成的高质量回答进行微调,这些回答在多个来源中提供了最高质量。
- 保留在0-hero/Matter-0.1项目中高评分的指令,以确保质量。
2. 偏好学习 (Preference Learning)
数据集:
- 使用UltraMedical偏好数据进行训练,包含约100K条指令,每条指令包含一个选择和一个拒绝回答。
优化技术:
- 直接偏好优化 (Direct Preference Optimization, DPO) 和 Kahneman-Tversky优化 (KTO):
- 每个指令关联八个完成项,生成二元偏好对。
- 结合通用偏好数据集(如UltraFeedback、UltraInteract、UltraSafety),总计约75K条指令。
3. 奖励建模 (Reward Modeling)
目标:
- 奖励模型是强化学习、人类反馈拒绝采样微调、迭代直接偏好优化等技术的核心组成部分。
训练过程:
- 使用UltraMedical偏好数据训练奖励模型,并增强其在通用聊天、安全和推理方面的能力。
- 模型用于标注UltraMedical LMs的回答,并提供“在线”偏好数据对。
4. 迭代偏好学习 (Iterative Preference Learning)
在线偏好学习:
- 进行推理并生成完成项,将生成的完成项和参考答案标注为“选择”与“拒绝”。
- 基于奖励模型的偏好数据进行偏好学习,反复进行K次,得到最终的UltraMedical LM。
最佳N采样 (Best of N Sampling):
- 使用奖励模型从N个采样候选中选择最佳完成项,适用于推理和训练过程中。
5.实验结果
基于Llama-3系列进行微调的UltraMedical模型在多个医学基准测试中表现出色,特别是在MedQA、MedMCQA和MMLU等基准测试中,显著优于许多现有的模型。这些结果表明,通过高质量的数据集和多步优化策略,可以大幅提升开源医学模型的性能。
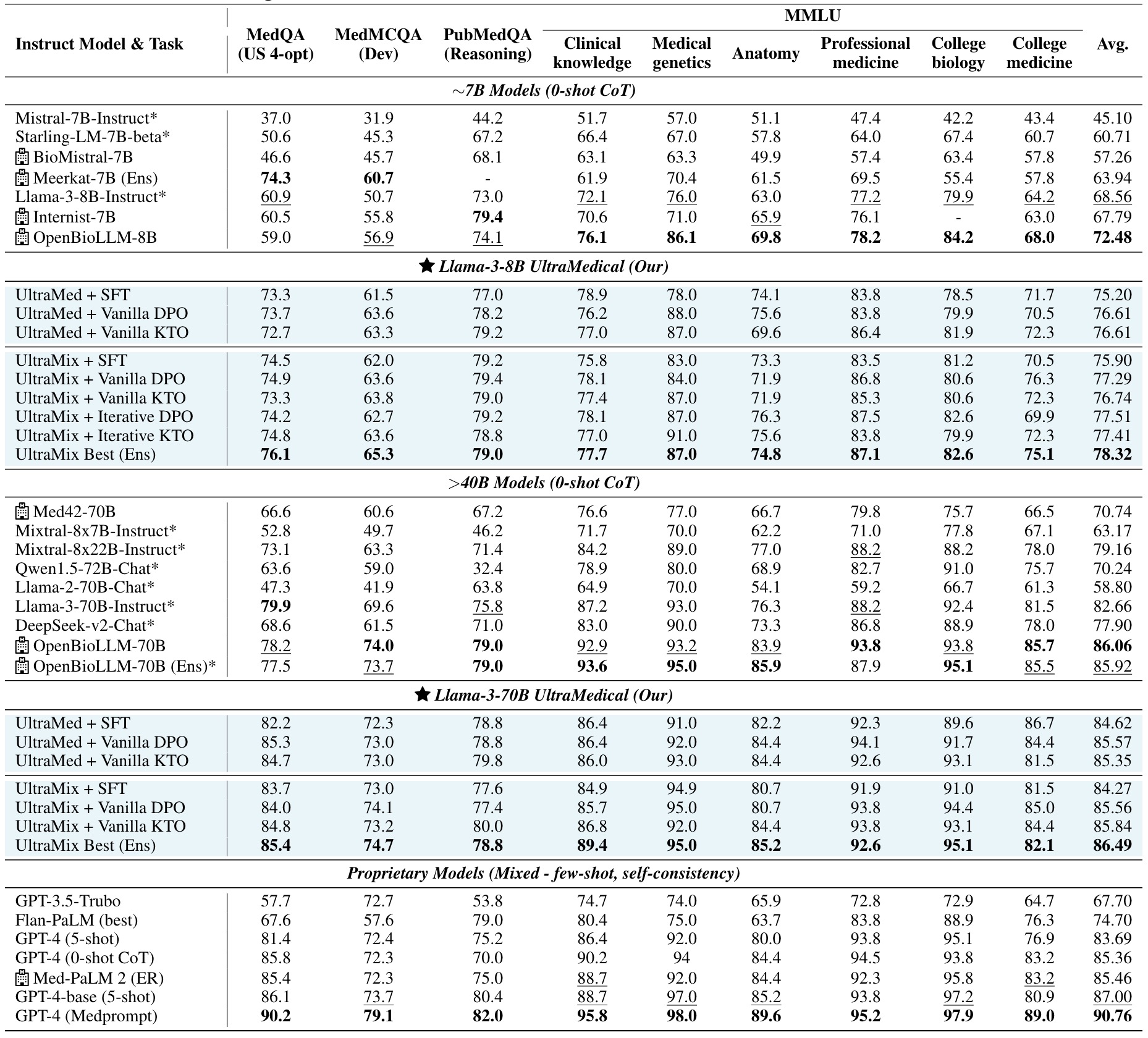
评估基准:
- 医学领域:MedQA、PubMedQA、MedMCQA、MMLU医学类目(临床知识、医学遗传学、解剖学、专业医学、大学生物学、大学医学)。
- 通用领域:MT-Bench、Alpaca-Eval、MMLU通用类目、GPQA、GSM8k。
1. 医学多项选择题结果
| 模型 | MedQA | MedMCQA | PubMedQA | MMLU-临床知识 | MMLU-医学遗传学 | MMLU-解剖学 | MMLU-专业医学 | MMLU-大学生物学 | MMLU-大学医学 | MMLU平均 |
|---|---|---|---|---|---|---|---|---|---|---|
| Llama-3-8B | 60.9 | 50.7 | 73.0 | 72.1 | 76.0 | 63.0 | 77.2 | 79.9 | 64.2 | 68.56 |
| Llama-3-8B UltraMedical | 73.3 | 61.5 | 77.0 | 78.9 | 78.0 | 74.1 | 83.8 | 78.5 | 71.7 | 75.20 |
| Llama-3-8B UltraMix | 74.5 | 62.0 | 79.2 | 75.8 | 83.0 | 73.3 | 83.5 | 81.2 | 70.5 | 75.90 |
| Llama-3-70B | 79.9 | 69.6 | 75.8 | 87.2 | 93.0 | 76.3 | 88.2 | 92.4 | 81.5 | 82.66 |
| Llama-3-70B UltraMedical | 82.2 | 72.3 | 78.8 | 86.4 | 91.0 | 82.2 | 92.3 | 89.6 | 86.7 | 84.62 |
| Llama-3-70B UltraMix | 83.7 | 73.0 | 77.6 | 84.9 | 94.9 | 80.7 | 91.9 | 91.0 | 81.5 | 84.27 |
2. 通用领域基准测试结果
| 模型 | K-QA | MT-Bench | AlpacaEval | MMLU (LC%) | GPQA (WR%) | GSM8K (5-shot) |
|---|---|---|---|---|---|---|
| Llama-3-8B | 0.6037 | 0.1940 | 8.10 | 22.9 | 22.6 | 68.4 |
| Llama-3-8B UltraMedical | 0.7242 | 0.0945 | 7.64 | 30.7 | 31.9 | 68.1 |
| Llama-3-8B UltraMix | 0.7242 | 0.0945 | 7.64 | 30.7 | 31.9 | 68.1 |
| Llama-3-70B | 0.6545 | 0.1357 | 9.01 | 34.4 | 33.2 | 82.0 |
| Llama-3-70B UltraMedical | 0.6077 | 0.0896 | 8.54 | 33.0 | 32.1 | 77.2 |
| Llama-3-70B UltraMix | 0.6077 | 0.0896 | 8.54 | 33.0 | 32.1 | 77.2 |
数据混合策略的影响
- UltraMedical 数据集:专注于医学指令,显著提升了Llama-3模型在医学领域的表现。
- UltraMix 数据集:结合医学和通用指令,进一步提升了模型在医学和通用领域的表现,表明混合数据策略对于提升模型整体性能的重要性。
偏好优化的有效性
- 使用偏好优化技术(如DPO和KTO)对模型进行微调,进一步提升了模型在医学任务中的表现,特别是在复杂问题上的表现。
- 迭代偏好学习通过在线生成和评估模型的完成项,显著提升了模型的表现。
医学与通用领域性能权衡
- UltraMedical LMs在医学任务中的表现优异,同时在通用领域基准测试中的表现略有下降。这显示了专用通用语言模型在医学和通用任务中的潜力和必要性。
3.两款模型具体表现
- 小规模语言模型 (7B级别)
UltraMedical训练和发布了一系列小规模的语言模型,其中表现最好的模型是Meta-Llama-3-8B。这些模型在多个流行的医学基准测试中表现优异,包括MedQA、MedMCQA、PubMedQA和MMLU-Medical。
Demo: Huggingface Space – Huggingface: Llama-3-8B-UltraMedical
模型表现统计:
| 版本 | 模型 | 平均成绩 | MedQA | MedMCQA | PubMedQA | MMLU.ck | MMLU.mg | MMLU.an | MMLU.pm | MMLU.cb | MMLU.cm |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2024.04 | Llama-3-8B-UltraMedical (Ensemble) | 77.77 | 77.5 | 63.8 | 78.2 | 77.4 | 88.0 | 74.8 | 84.6 | 79.9 | 75.7 |
| 2024.04 | Llama-3-8B-UltraMedical (Greedy) | 75.20 | 73.3 | 61.5 | 77.0 | 78.9 | 78.0 | 74.1 | 83.8 | 78.5 | 71.7 |
| 2024.04 | OpenBioLM-8B | 72.48 | 59.0 | 56.9 | 74.1 | 76.1 | 86.1 | 69.8 | 78.2 | 84.2 | 68.0 |
| 2024.04 | Llama-3-8B-Instruct (Ensemble) | 71.23 | 62.4 | 56.5 | 75.8 | 72.5 | 84.0 | 71.1 | 70.6 | 80.6 | 67.6 |
| 2024.04 | Llama-3-8B-Instruct (Greedy) | 68.56 | 60.9 | 50.7 | 73.0 | 72.1 | 76.0 | 63.0 | 77.2 | 79.9 | 64.2 |
| 2024.04 | Internist-7B | 67.79 | 60.5 | 55.8 | 79.4 | 70.6 | 71.0 | 65.9 | 76.1 | – | 63.0 |
| 2024.02 | Gemma-7B | 64.18 | 47.2 | 49.0 | 76.2 | 69.8 | 70.0 | 59.3 | 66.2 | 79.9 | 60.1 |
| 2024.03 | Meerkat-7B (Ensemble) | 63.94 | 74.3 | 60.7 | – | 61.9 | 70.4 | 61.5 | 69.5 | 55.4 | 57.8 |
| 2023.03 | MedAlpaca | 58.03 | 41.7 | 37.5 | 72.8 | 57.4 | 69.0 | 57.0 | 67.3 | 65.3 | 54.3 |
| 2024.02 | BioMistral-7B | 57.26 | 46.6 | 45.7 | 68.1 | 63.1 | 63.3 | 49.9 | 57.4 | 63.4 | 57.8 |
- Llama-3-8B-UltraMedical (Ensemble):采用了集成策略,在多个医学基准测试中取得了77.77的平均成绩,是表现最好的7B级别模型。
- Llama-3-8B-UltraMedical (Greedy):采用贪婪搜索策略,取得了75.20的平均成绩。
- OpenBioLM-8B:在多个医学基准测试中取得了72.48的平均成绩。
- Llama-3-8B-Instruct (Ensemble) 和 Llama-3-8B-Instruct (Greedy):分别取得了71.23和68.56的平均成绩。
- Internist-7B、Gemma-7B、Meerkat-7B (Ensemble)、MedAlpaca、BioMistral-7B:这些模型的平均成绩从67.79到57.26不等。
大规模语言模型 (70B级别)
UltraMedical还计划发布一系列大规模的语言模型,如Llama-3-70B-UltraMedical。这些模型预计将在未来几个月内发布。
模型表现统计:
| 版本 | 模型 | 平均成绩 | MedQA | MedMCQA | PubMedQA | MMLU.ck | MMLU.mg | MMLU.an | MMLU.pm | MMLU.cb | MMLU.cm |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2023.11 | GPT-4 (Medprompt) | 90.76 | 90.2 | 79.1 | 82.0 | 95.8 | 98.0 | 89.6 | 95.2 | 97.9 | 89.0 |
| 2023.06 | GPT-4-base (5-shot) | 87.00 | 86.1 | 73.7 | 80.4 | 88.7 | 97.0 | 85.2 | 93.8 | 97.2 | 80.9 |
| 2023.04 | Med-PaLM 2 (best) | 86.66 | 86.5 | 72.3 | 81.8 | 88.7 | 92.0 | 84.4 | 95.2 | 95.8 | 83.2 |
| 2024.04 | OpenBioLM-70B | 86.06 | 78.2 | 74.0 | 79.0 | 92.9 | 93.2 | 83.9 | 93.8 | 93.8 | 85.7 |
| 2023.04 | Med-PaLM 2 (ER) | 85.46 | 85.4 | 72.3 | 75.0 | 88.7 | 92.0 | 84.4 | 92.3 | 95.8 | 83.2 |
| 2023.03 | GPT-4 (0-shot CoT) | 85.36 | 85.8 | 72.3 | 70.0 | 90.2 | 94.0 | 84.4 | 94.5 | 93.8 | 83.2 |
| 2023.03 | GPT-4 (5-shot) | 83.69 | 81.4 | 72.4 | 75.2 | 86.4 | 92.0 | 80.0 | 93.8 | 95.1 | 76.9 |
| 2024.04 | Llama-3-70B-Instruct | 82.66 | 79.9 | 69.6 | 75.8 | 87.2 | 93.0 | 76.3 | 88.2 | 92.4 | 81.5 |
| 2022.10 | Flan-PaLM (best) | 74.70 | 67.6 | 57.6 | 79.0 | 80.4 | 75.0 | 63.7 | 83.8 | 88.9 | 76.3 |
| 2024.04 | Mixtral-8x22B-Instruct | 73.10 | 63.3 | 71.4 | 84.2 | 89.0 | 77.0 | 88.2 | 88.2 | 78.0 | 79.2 |
| 2022.11 | GPT-3.5-Trubo | 67.70 | 57.7 | 72.7 | 53.8 | 74.7 | 74.0 | 65.9 | 72.8 | 72.9 | 64.7 |
| 2023.11 | Meditron-70B | 66.00 | 57.7 | 53.8 | 72.7 | 66.8 | 69.0 | 53.3 | 71.7 | 76.4 | 63.0 |
- GPT-4 (Medprompt):在多个医学基准测试中取得了90.76的平均成绩,是目前表现最好的模型。
- GPT-4-base (5-shot) 和 Med-PaLM 2 (best):分别取得了87.00和86.66的平均成绩。
- OpenBioLM-70B:在多个医学基准测试中取得了86.06的平均成绩。
- Llama-3-70B-Instruct:在多个医学基准测试中取得了82.66的平均成绩。
- Flan-PaLM (best) 和 Mixtral-8x22B-Instruct:分别取得了74.70和73.10的平均成绩。
- GPT-3.5-Trubo 和 Meditron-70B:分别取得了67.70和66.00的平均成绩。














{kind=link}