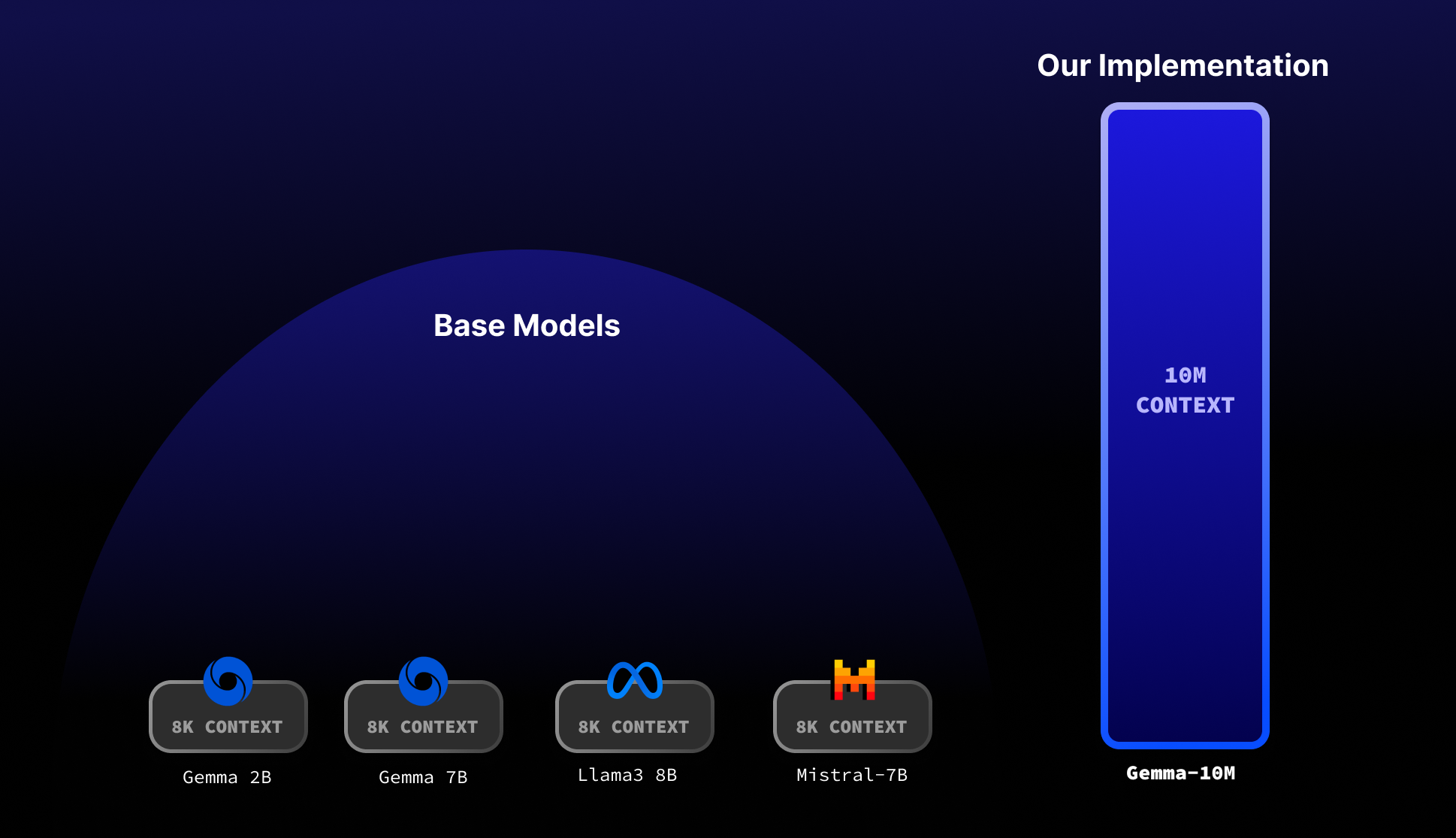
<p data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">Gemma-10M 模型使用一种称为 Infini-Attention 的技术,将 Gemma 2B 的上下文窗口扩展到 10M。其主要方法是通过循环局部注意力和压缩记忆,实现长距离依赖关系的保留。</p> <p data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"><strong data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">特性:</strong></p> <ul data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">支持高达1000万长度的序列。</li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">使用不超过32GB内存。</li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">针对CUDA进行本地推理优化。</li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">使用递归局部注意力,实现O(N)内存占用。</li> </ul> <ul data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83"> <li data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83" data-immersive-translate-paragraph="1"><strong data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">Github</strong>: <a href="https://github.com/mustafaaljadery/gemma-10M-mlx/" target="_new" rel="noreferrer noopener" data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">https://github.com/mustafaaljadery/gemma-10M-mlx/</a><span class="notranslate immersive-translate-target-wrapper" lang="zh-CN" data-immersive-translate-translation-element-mark="1"> </span></li> <li data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83" data-immersive-translate-paragraph="1"><strong data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">HuggingFace</strong>: <a href="https://huggingface.co/mustafaaljadery/gemma-10M-safetensor" target="_new" rel="noreferrer noopener" data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">https://huggingface.co/mustafaaljadery/gemma-10M-safetensor</a></li> </ul> <p data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">Transformer模型虽然强大,但计算和内存成本极高,特别是对于现代大语言模型中的上下文扩展而言更具挑战性。Gemma-10M结合了循环神经网络与局部注意力的优势,能够在内存和计算成本大幅降低的情况下扩展到任意上下文窗口尺寸。</p> <p data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"><strong>具体来说:</strong></p> <ol data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <p data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"><strong data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">循环局部注意力:</strong> Transformer的KV缓存在长序列处理时会导致计算成本和内存占用急剧增加,而Gemma-10M利用了循环局部注意力,通过分块的方式解决了这一问题。使用循环神经网络的原理,将局部注意力块压缩成状态向量,然后将其传递到下一个块。这样,模型可以保持较小的内存占用,并记住先前的上下文信息。</p> </li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <p data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"><strong data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">Infini-Attention 技术:</strong>借鉴Google的 <a href="https://arxiv.org/abs/2404.07143" rel="nofollow" data-immersive-translate-walked="69769c23-8cd4-4ef9-9f4a-61d78e3273de">InfiniAttention </a>研究,Gemma-10M采用了压缩记忆策略,将之前层级的信息存储到一个压缩的矩阵中,以减少计算量和内存占用,实现更高效的上下文处理。 基于压缩记忆技术,模型能够对当前块执行标准的自注意力,并对之前的状态进行线性注意力。这使得模型可以扩展到任意大小的上下文窗口。</p> </li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <p data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"><strong data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">逐步扩展训练:</strong> 通过逐渐增加上下文窗口的大小(从 32K 到 10M),使模型能够逐步学习复杂的长序列上下文表示。模型能够优先学习到较短序列的嵌入表示,为之后的长序列学习奠定基础,提高训练效率。</p> </li> </ol> 很多想法灵感都来自于 <a href="https://arxiv.org/abs/1901.02860" rel="nofollow" data-immersive-translate-walked="69769c23-8cd4-4ef9-9f4a-61d78e3273de">Transformer-XL</a> 论文。 <p data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"><strong>Gemma-10M 在以下方面带来了性能提升和变化:</strong></p> <ol data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <p data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"><strong data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">上下文保留能力增强:</strong></p> <ul data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">增加的上下文窗口长度使模型能够更好地保留上下文信息,尤其是对于需要长距离依赖的任务(如长文生成和复杂问题回答),可以有效地利用更多上下文。</li> </ul> </li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <p data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"><strong data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">更准确的推理和生成:</strong></p> <ul data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">更大的上下文窗口意味着模型可以参考更长的先前文本,从而生成更连贯和准确的输出。文本生成任务如小说、报告等都能受益于此。</li> </ul> </li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <p data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"><strong data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">更广泛的任务适应性:</strong></p> <ul data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">扩展后的上下文窗口可以涵盖更多种类的任务,包括代码生成、长对话分析、复杂文档摘要等。</li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">模型可以适应更复杂的数据结构。</li> </ul> </li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <p data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"><strong data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">资源利用优化:</strong></p> <ul data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">虽然上下文窗口扩展到 10M,但通过 Infini-Attention 和递归局部注意力的优化技术,Gemma-10M 模型能够保持较低的内存和计算成本。</li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">仍保持O(1) 内存和 O(n) 时间的计算复杂度,使其能够在消费级硬件上运行。</li> </ul> </li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <p data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"><strong data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">更高效的训练流程:</strong></p> <ul data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">渐进式的训练策略使模型能够逐步适应更大的上下文窗口。先从较短的序列预训练,确保初始嵌入表示较为稳固,再逐渐扩展到更长的上下文,从而节省了训练成本。</li> </ul> </li> </ol> <h3 data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">技术方法</h3> <p data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">Gemma-10M 使用了一种名为 Infini-Attention 的技术,将上下文窗口扩展到 10M。其技术方法和原理如下:</p> <ol data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <p data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"><strong data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">标准 Transformer 模型的挑战:</strong></p> <ul data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">Transformer 模型的多头注意力机制对序列长度的扩展具有挑战性,尤其是由于键值缓存的大小会随着序列长度呈二次增长。</li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">计算的主要瓶颈在于这类键值缓存(KV 缓存)会在注意力表中存储先前令牌的键和值,并用于计算最新令牌的注意力。</li> </ul> </li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <p data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"><strong data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">循环局部注意力:</strong></p> <ul data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">受 <a href="https://arxiv.org/abs/1901.02860" rel="nofollow" data-immersive-translate-walked="69769c23-8cd4-4ef9-9f4a-61d78e3273de">Transformer-XL</a> 模型和循环神经网络的启发,Gemma-10M 使用递归注意力机制。具体来说,它在局部块(如 2048x2048)中计算注意力,并将结果传递给一个多层感知机(MLP)以生成状态向量。</li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">这个状态向量作为额外的输入传递到下一个局部注意力块中,从而在序列的不同部分间保留长距离依赖关系。</li> </ul> <p data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"><strong data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">示意图:</strong></p> <ul data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"><strong data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">块 1</strong>:计算局部注意力,将其结果传递到 MLP,生成状态向量。</li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"><strong data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">块 2</strong>:从块 1 处获得状态向量作为输入,然后计算当前块的局部注意力。</li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"><strong data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">块 3</strong>:重复这个过程,并保留对上一个块的状态记忆。<img class="aligncenter size-full wp-image-7747" src="https://img.xiaohu.ai/2024/05/1_tsjA65aG4kuhqGnW3Vmfmw.png" alt="" width="700" height="306" /></li> </ul> <p data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"><strong data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">优点:</strong></p> <ul data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">通过丢弃之前的块缓存,只保留当前块和上一个块的状态记忆,减小了内存开销。</li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">这种方式能够让模型在较低内存消耗的情况下处理更大的上下文窗口。</li> </ul> </li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <p data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"><strong data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959" data-immersive-translate-paragraph="1">Infini-Attention:</strong></p> <ul data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">借鉴谷歌的 Infini-Attention 论文,该技术使用压缩记忆方法存储先前的状态信息。</li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">模型通过对当前块执行标准自注意力和对压缩记忆执行线性注意力,来实现长距离上下文的关注。</li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">该方法允许模型既能进行局部注意力,又能保持对过去块信息的线性访问。</li> </ul> <p data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"><strong data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">示意图:</strong></p> <ul data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">当前块的查询-键值对(Q-KV)执行标准自注意力。</li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">同时,使用线性注意力访问先前的压缩记忆。<img class="aligncenter size-full wp-image-7745" src="https://img.xiaohu.ai/2024/05/0_j3rItBAuZalLF6Is.jpg" alt="" width="632" height="584" /></li> </ul> </li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <p data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"><strong data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">渐进式上下文窗口训练:</strong></p> <ul data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">逐步扩展上下文窗口,从 32K 到 10M 的窗口大小逐级增长。</li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">起初在较短序列上预训练以获得基本的嵌入表示,逐渐扩展窗口时可以更有效地学习长距离表示。</li> </ul> <p data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"><strong data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">原理:</strong></p> <ul data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959"> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">初始训练较小窗口,以学习到有效的上下文表示。</li> <li data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">更大窗口的训练能够利用已存在的表示进行更复杂的学习。</li> </ul> </li> </ol> <p data-immersive-translate-walked="2c1fee5a-5bff-4fc1-aa58-cafb7a421959">通过这种方法,Gemma-10M 能够有效利用递归局部注意力和压缩记忆技术,在保持较低内存占用的情况下扩展上下文窗口至 10M。</p> <hr /> <h2 data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">以下是官方实施细节和工作背后的理论概述</h2> <h2 data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">动机</h2> <p data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">虽然Transformer模型强大,但其计算需求非常高,计算时间和内存占用随Token数量呈<strong data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">O(n²)级增长</strong>。这使得在现代大语言模型 (LLM) 中扩展上下文窗口变得极具挑战。在Gemma-10M模型中,我们结合了循环神经网络 (Recurrent Neural Network) 与局部注意力块的洞见,以<strong data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">O(1)内存</strong>和<strong data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">O(n)时间</strong>捕获长期知识,从而允许模型扩展到任意上下文窗口尺寸。</p> <p data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">在以下平台上查看:</p> <ul data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83"> <li data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83" data-immersive-translate-paragraph="1"><strong data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">Github</strong>: <a href="https://github.com/mustafaaljadery/gemma-10M-mlx/" target="_new" rel="noreferrer noopener" data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">https://github.com/mustafaaljadery/gemma-10M-mlx/</a></li> <li data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83" data-immersive-translate-paragraph="1"><strong data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">HuggingFace</strong>: <a href="https://huggingface.co/mustafaaljadery/gemma-10M-safetensor" target="_new" rel="noreferrer noopener" data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">https://huggingface.co/mustafaaljadery/gemma-10M-safetensor</a><span class="notranslate immersive-translate-target-wrapper" lang="zh-CN" data-immersive-translate-translation-element-mark="1"> </span></li> </ul> <h2 data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">概要</h2> <ol data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83"> <li data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">标准Transformer的挑战</li> <li data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">循环注意力</li> <li data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">无限注意力</li> <li data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">增量上下文尺寸训练</li> </ol> <h2 data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">标准Transformer的挑战</h2> <p data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">扩展标准Transformer模型的最大瓶颈是KV缓存(KV-Cache)尺寸的扩展问题。KV缓存存储前面Token的Key-Value对,供计算最新Token的注意力时使用。如果不这样做,会显著增加计算成本,使处理较长序列几乎不可行。下面的GIF图演示了KV缓存的概念。</p> <p data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83"><img class="aligncenter size-large wp-image-7749" src="https://img.xiaohu.ai/2024/05/1_uyuyOW1VBqmF5Gtv225XHQ-1-1024x576.gif" alt="" width="1024" height="576" /></p> <p data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">然而,存储这些缓存的成本极高——尤其在上下文长度达到1M时,缓存总数将达到1,000,000 x 1,000,000 = 12万亿项,难以在常规硬件上容纳。</p> <h2 data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">循环局部注意力</h2> <p data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">借鉴Transformer-XL和循环神经网络的洞见,我们在2048 x 2048的局部块中计算注意力,并将结果传递到多层感知器 (MLP) 中,以存储状态向量。这个状态向量被作为额外参数传递到我们计算的下一个局部注意力块,以保留Token序列中较早的记忆。</p> <p data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83"><img class="aligncenter size-full wp-image-7747" src="https://img.xiaohu.ai/2024/05/1_tsjA65aG4kuhqGnW3Vmfmw.png" alt="" width="700" height="306" /></p> <p data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">通过丢弃之前的缓存,可以消除扩展窗口尺寸带来的内存开销。这样就可以将任意大的上下文尺寸装入普通硬件,使我们能够使用32GB内存运行Gemma 2B-10M模型!</p> <p data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">此外,我们在推理时间上也节省了大量成本。密集注意力块需要计算n²项,而我们的方法将原始矩阵分解成稀疏对角块矩阵,计算这些块所需的计算量大大减少。对于尺寸为d的注意力块,有n/d个块,总共有d² * n/d = nd项参数。这样,总的执行浮点运算量从O(n²)降低到O(nd),特别是在n远大于d时,性能提升显著。</p> <p data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83"><img class="aligncenter size-full wp-image-7746" src="https://img.xiaohu.ai/2024/05/1_SWa5l60fVtOyrZtny6m7tw.png" alt="" width="700" height="318" /></p> <h2 data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">无限注意力</h2> <p data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">在循环状态向量的实用性得到验证后,接下来讨论我们具体如何实现它。借鉴Google的开创性无限注意力论文,我们使用压缩记忆来存储先前层的信息。这样,我们的模型只需在局部块上执行标准点积(二次注意力),并线性访问过去的压缩记忆。</p> <p data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83"><img class="aligncenter size-full wp-image-7745" src="https://img.xiaohu.ai/2024/05/0_j3rItBAuZalLF6Is.jpg" alt="" width="632" height="584" /></p> <p data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">这引出了一个关键问题:压缩记忆如何运作?数学细节较为复杂,但我们会提供一些直观的解释。在每一层中,我们将Key-Value对添加到矩阵中。假设第二层的记忆矩阵为M0 + v1 k1 + v2 k2,如果键相互正交,则可以通过简单的点积检索与键相关的值,类似于傅里叶变换中恢复系数的方式。</p> <p data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83"><img src="https://miro.medium.com/v2/resize:fit:160/0*PfaAfFjI_86On5jQ.png" alt="压缩记忆矩阵" /></p> <p data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">为了优化KV检索效率,我们应用内核到查询和键中,从而将softmax操作作为内核的仿射变换来学习。我们使用内核σ,完成我们对记忆的更新规则。</p> <p data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83"><img class="aligncenter size-full wp-image-7744" src="https://img.xiaohu.ai/2024/05/1_lYwvEYBWxDmncJC-Dp56VA.png" alt="" width="700" height="102" /></p> <h2 data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83"><strong data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">渐进式扩展上下文窗口</strong></h2> <p data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">为了优化训练成本和数据,我们采用了GrowLength的方法,逐渐将上下文尺寸从32K增加到64K、128K、256K、512K、1M、2M、4M,再到10M。这使得我们在最初以较短序列优先训练,从而更高效利用资源,获得更简单的表示嵌入。当上下文窗口扩大时,我们利用更强大的初始表示状态,使得较大窗口尺寸的训练更简单。</p> <p data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83"><img class="aligncenter size-full wp-image-7743" src="https://img.xiaohu.ai/2024/05/1_weNk7-edA7fweagyt3kdyQ.png" alt="" width="700" height="89" /></p> <p data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">在模型的第一个层级中,学习到的上下文窗口长度最多为32k,这使得下一层学习64k的窗口更容易,因为底层表示已经丰富了。一般来说,在第N层,N-1层所学的模式使我们能够有效扩展,而不需要一次性学习复杂的百万Token表示。</p> <p data-immersive-translate-walked="cdc82821-75e6-4e59-b969-61c678421c83">原文:<a href="https://medium.com/@akshgarg_36829/gemma-10m-technical-overview-900adc4fbeeb" target="_blank" rel="noopener">https://medium.com/@akshgarg_36829/gemma-10m-technical-overview-900adc4fbeeb</a></p>






{kind=link}