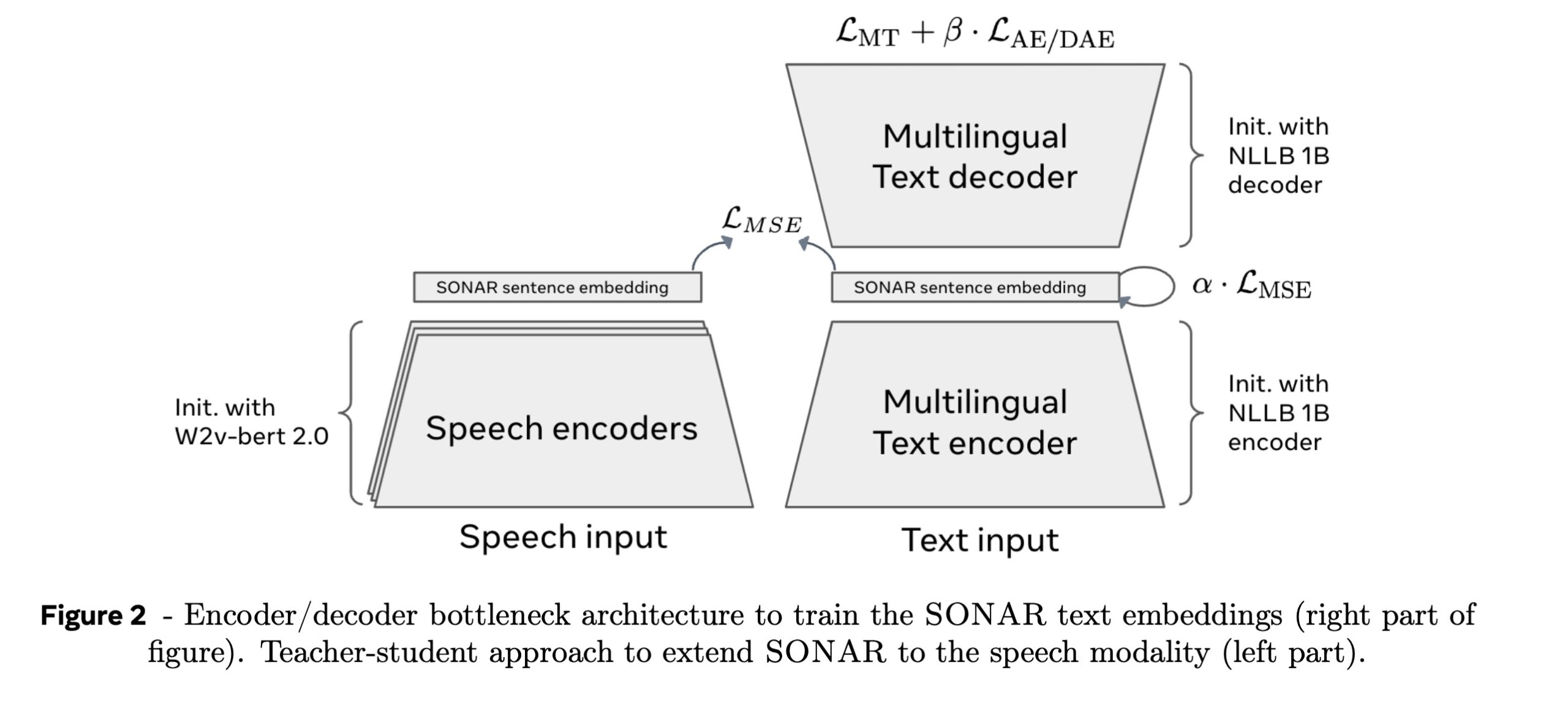
当前的大型语言模型(LLMs)虽然在多任务处理上表现优异,但其主要依赖于基于单词或子词的逐步生成,与人类多层次抽象推理能力存在差距。 <strong>传统LLMs的局限性</strong> <ul> <li><strong>缺乏多层次推理能力</strong>:传统LLMs(如GPT、Claude)在文本生成时逐字预测,虽然效果流畅,但缺乏显式的层次化规划能力。</li> <li><strong>语言中心化问题</strong>:多数LLMs以英语为中心,对低资源语言的支持较弱。</li> <li><strong>长文本生成一致性问题</strong>:在生成长文本时,传统LLMs难以保持逻辑一致性。</li> </ul> 人类在处理复杂任务时,通常从高层次概念规划入手,再逐步细化,而现有LLMs缺乏显式的层次化结构。 Meta AI提出了一种新的大语言模型架构“Large Concept Model (LCM)”,旨在以更高层次的语义表示(概念 concept)进行推理和生成,跨越语言和模态的限制。 与传统语言模型(比如GPT)逐字生成不同,LCM的核心理念是基于“概念”(concept)进行语言处理,把每个句子看作一个“概念”concept),在句子级别进行推理和生成,而不是传统模型的“词元”(token)级别操作。它的目标是让模型更像人类思考,先从大框架入手,再填充细节。 具体来说: <ul> <li><strong>概念(Concept)</strong>:在LCM中,一个概念通常对应一个完整的句子,它是语言和模态无关的高级语义表示。</li> <li><strong>设计目标</strong>:从更高的抽象层次进行推理和生成,超越现有模型局限,处理更复杂的任务。</li> </ul> <img class="aligncenter size-full wp-image-16124" src="https://img.xiaohu.ai/2024/12/Jietu20241224-202607@2x.jpg" alt="" width="2534" height="1372" />LCM通过SONAR嵌入空间对句子进行编码,将文本或语音输入转换为高维语义嵌入,在这些嵌入上进行推理和生成。这使得模型能够直接在句子级别处理信息,而非逐字生成。 <ul> <li>思考方式像人类,从“概念”出发,逻辑更清晰。</li> <li>能处理多语言、多模态任务,直接支持文本、语音甚至手语。</li> <li>适合长文本处理,速度快,生成内容更连贯。</li> <li>具备强大的零样本泛化能力,不用额外训练也能完成新任务。</li> </ul> <table> <thead> <tr> <th><strong>对比项</strong></th> <th><strong>传统模型 (GPT)</strong></th> <th><strong>LCM</strong></th> </tr> </thead> </table> <div> <table> <tbody> <tr> <td><strong>生成单位</strong></td> <td>单词或词元逐字生成</td> <td>句子或段落级别生成</td> </tr> </tbody> </table> </div> <div> <table> <tbody> <tr> <td><strong>多语言支持</strong></td> <td>英语为主,部分支持</td> <td>支持200种语言</td> </tr> </tbody> </table> </div> <div> <table> <tbody> <tr> <td><strong>生成连贯性</strong></td> <td>长文本逻辑容易混乱</td> <td>逻辑更清晰,一致性强</td> </tr> </tbody> </table> </div> <div> <table> <tbody> <tr> <td><strong>上下文处理</strong></td> <td>长上下文性能下降</td> <td>更好处理长上下文</td> </tr> </tbody> </table> </div> <div> <table> <tbody> <tr> <td><strong>扩展能力</strong></td> <td>需重新训练或微调</td> <td>可直接泛化到新任务</td> </tr> </tbody> </table> </div> <h3><strong>LCM 解决了什么问题</strong></h3> <ol> <li><strong>传统LLMs的局限性</strong> <ul> <li><strong>缺乏多层次推理能力</strong>:传统LLMs(如GPT、Claude)在文本生成时逐字预测,虽然效果流畅,但缺乏显式的层次化规划能力。</li> <li><strong>语言中心化问题</strong>:多数LLMs以英语为中心,对低资源语言的支持较弱。</li> <li><strong>长文本生成一致性问题</strong>:在生成长文本时,传统LLMs难以保持逻辑一致性。</li> </ul> </li> <li><strong>LCM如何改进</strong> <ul> <li><strong>显式推理</strong>:通过引入层次化结构,LCM能够在概念级别规划文本的整体结构和逻辑。</li> <li><strong>多语言和模态支持</strong>:LCM基于SONAR嵌入,支持200种语言,能够无缝处理多种模态(如文本、语音)。</li> <li><strong>提高生成效率和一致性</strong>:LCM以句子为单位进行推理,显著降低序列长度,减小计算复杂度,同时提高生成的连贯性。</li> </ul> </li> </ol> 论文中探索了以下 <strong>三种主要模型架构</strong>,它们分别是针对不同任务需求设计的: <div class="flex max-w-full flex-col flex-grow"> <div class="min-h-8 text-message flex w-full flex-col items-end gap-2 whitespace-normal break-words text-start [.text-message+&]:mt-5" dir="auto" data-message-author-role="assistant" data-message-id="bb67ad61-cf1a-4838-bcf6-0734887cbe0c" data-message-model-slug="gpt-4o"> <div class="flex w-full flex-col gap-1 empty:hidden first:pt-[3px]"> <div class="markdown prose w-full break-words dark:prose-invert light"> <ul> <li><strong>基础模型 (Base-LCM)</strong>:结构简单,适合对精确性要求高但逻辑不复杂的任务。</li> <li><strong>扩散模型 (Diffusion LCM)</strong>:综合表现最佳,适合复杂逻辑和长文本生成。</li> <li><strong>量化模型 (Quantized LCM)</strong>:效率优先,适合多样性生成和低计算资源场景。</li> </ul> </div> </div> </div> </div> <div class="mb-2 flex gap-3 empty:hidden -ml-2"> <div class="items-center justify-start rounded-xl p-1 flex"></div> </div> <hr /> <strong>1. 基础模型 (Base-LCM)</strong> <ul> <li><strong>核心特点</strong>: <ul> <li>基于标准的自回归 Transformer 模型。</li> <li>使用均方误差 (MSE) 作为目标函数,直接预测下一句的语义嵌入。</li> </ul> </li> <li><strong>优势</strong>: <ul> <li>实现简单,生成嵌入的精确性较高(L2 距离最低)。</li> </ul> </li> <li><strong>劣势</strong>: <ul> <li>缺乏多样性:容易生成平均化的结果,不符合真实语义分布。</li> <li>上下文关联性较弱,生成长文本时逻辑一致性较差。</li> </ul> </li> </ul> <hr /> <strong>2. 基于扩散的模型 (Diffusion LCM)</strong> <ul> <li><strong>核心特点</strong>: <ul> <li>借鉴图像生成中的扩散模型(Diffusion Models)。</li> <li>在扩散过程的嵌入空间中逐步生成下一句的语义嵌入。</li> </ul> </li> <li><strong>模型变体</strong>: <ul> <li><strong>单塔模型 (One-Tower)</strong>:使用单一 Transformer 处理上下文和目标生成。</li> <li><strong>双塔模型 (Two-Tower)</strong>:上下文编码和目标生成分离: <ul> <li>第一塔负责提取上下文语义信息。</li> <li>第二塔通过扩散过程生成下一句的嵌入。</li> </ul> </li> </ul> </li> <li><strong>优势</strong>: <ul> <li>上下文关联性强,生成结果连贯性和多样性优秀。</li> <li>特别适合长文本生成和复杂逻辑任务。</li> </ul> </li> <li><strong>劣势</strong>: <ul> <li>计算复杂度相对较高。</li> </ul> </li> </ul> <hr /> <strong>3. 量化模型 (Quantized LCM)</strong> <ul> <li><strong>核心特点</strong>: <ul> <li>通过残差向量量化 (Residual Vector Quantization, RVQ),将嵌入离散化。</li> <li>使用离散单元进行推理和生成,输出可以是离散或连续的目标。</li> </ul> </li> <li><strong>模型变体</strong>: <ul> <li><strong>离散目标 (Quantized-LCM-d)</strong>:通过分类预测下一个量化单元。</li> <li><strong>连续目标 (Quantized-LCM-c)</strong>:通过回归预测连续的目标嵌入。</li> </ul> </li> <li><strong>优势</strong>: <ul> <li>更高效的计算和存储,适合资源有限的场景。</li> <li>支持控制生成多样性(如通过温度或采样策略)。</li> </ul> </li> <li><strong>劣势</strong>: <ul> <li>在生成的语义精确性和连贯性上略逊于扩散模型。</li> </ul> </li> </ul> <h3><strong>LCM 的主要功能特点</strong></h3> <ul> <li><strong>特性</strong>:LCM 关注的是“概念”,即完整的句子或想法,而不是逐词处理。</li> <li><strong>优势</strong>:像人类一样,从整体思考问题,再逐步填充细节。 <ul> <li>例如,在写文章时,LCM 先确定大纲,再生成具体内容,使文章更有逻辑性。</li> </ul> </li> </ul> 以下是其主要功能特点: <hr /> <h5><strong>1. 语言和模态无关性</strong></h5> <ul> <li><strong>核心能力</strong>:LCM可以在多种语言和模态之间处理信息,而不依赖于具体的语言符号或格式。</li> <li><strong>支持范围</strong>: <ul> <li>200种语言的文本输入。</li> <li>76种语言的语音输入。</li> <li>可以跨语言生成,例如将中文语音转化为英文文本。</li> </ul> </li> <li><strong>典型场景</strong>: <ul> <li>多语言翻译:能够无缝处理低资源语言。</li> <li>多模态任务:未来可能支持视频或手语生成。</li> </ul> </li> </ul> <hr /> <h5><strong>2. 显式的层次化推理</strong></h5> <ul> <li><strong>层次化结构</strong>:LCM像人一样,从高层次的“概念”(句子级别)进行推理,再逐步细化到具体的生成内容。</li> <li><strong>解决的问题</strong>: <ul> <li>传统模型在长文本生成中,前后逻辑容易出现不一致。</li> <li>LCM可以先规划文本的大纲(如章节、段落),再生成具体内容。</li> </ul> </li> <li><strong>优势</strong>: <ul> <li>提高了长文本生成的连贯性和一致性。</li> <li>更容易进行局部编辑,例如修改一段内容时,不会破坏整体逻辑。</li> </ul> </li> </ul> <hr /> <h5><strong>3. 强大的零样本泛化能力</strong></h5> <ul> <li><strong>功能描述</strong>:无需对每种语言或任务进行额外微调,LCM在预训练后能直接应用到新的语言或任务。</li> <li><strong>效果</strong>: <ul> <li>跨语言生成:比如用德语的输入直接生成法语的输出。</li> <li>跨任务迁移:如从摘要生成任务迁移到长篇文章扩展任务。</li> </ul> </li> <li><strong>优势</strong>: <ul> <li>减少对大规模训练数据的依赖。</li> <li>适配性更强,适合复杂、多样化场景。</li> </ul> </li> </ul> <hr /> <h5><strong>4. 高效处理长文本</strong></h5> <ul> <li><strong>技术优化</strong>:LCM以句子为单位进行推理,而非传统模型的逐词生成,显著降低了计算复杂度。</li> <li><strong>表现</strong>: <ul> <li>更好地理解长上下文,提高对大段文字的生成质量。</li> <li>支持长文章生成,例如小说或学术论文的整体规划。</li> </ul> </li> <li><strong>应用场景</strong>: <ul> <li>生成连续性要求高的内容,如新闻稿、故事或技术文档。</li> </ul> </li> </ul> <hr /> <h5><strong>5. 模块化和可扩展性</strong></h5> <ul> <li><strong>模块化设计</strong>: <ul> <li>概念编码器(Concept Encoder):将句子转化为高维语义嵌入。</li> <li>概念推理器(Concept Reasoner):在嵌入空间中推理生成。</li> <li>概念解码器(Concept Decoder):将嵌入还原为自然语言。</li> </ul> </li> <li><strong>灵活扩展</strong>: <ul> <li>可以单独优化某个模块,例如新增对手语或视频模态的支持。</li> <li>易于添加新的语言或模态,且不会影响现有系统。</li> </ul> </li> </ul> <hr /> <h5><strong>6. 高级生成特性</strong></h5> <ul> <li><strong>多样性生成</strong>: <ul> <li>支持同时生成多个合理的内容版本(扩散模型支持)。</li> <li>比如同一个输入,可以生成不同风格或语言的输出。</li> </ul> </li> <li><strong>生成控制</strong>: <ul> <li>提供用户交互能力,可以局部调整生成结果。</li> <li>比如修改生成段落的语气、风格或语言。</li> </ul> </li> </ul> <hr /> <h5><strong>7. 提供开源工具与代码</strong></h5> <ul> <li>LCM的训练代码和SONAR嵌入库是开源的,支持研究人员和开发者在其基础上进一步开发和优化。</li> <li>开源工具支持多语言和多模态任务,降低了使用门槛。</li> </ul> <h3><strong>LCM 的工作原理</strong></h3> LCM(大型概念模型)的核心工作原理是通过“概念”(例如句子级别的抽象语义)进行推理和生成,而不是传统语言模型逐词生成的方式。这种方式更接近人类的思维方式,从高层抽象到细节逐步展开。 LCM 的架构包括以下主要模块: <ol> <li><strong>概念编码器 (Concept Encoder)</strong> <ul> <li>将输入的句子或语音转化为语义嵌入。</li> <li>使用 SONAR 嵌入空间,这是一种语言和模态无关的高维语义表示。</li> </ul> </li> <li><strong>概念推理器 (Concept Reasoner)</strong> <ul> <li>在嵌入空间中进行推理和生成。</li> <li>实现从上下文生成下一句嵌入的功能。</li> </ul> </li> <li><strong>概念解码器 (Concept Decoder)</strong> <ul> <li>将生成的嵌入还原为自然语言(文本或语音)。</li> </ul> </li> </ol> <img class="aligncenter size-full wp-image-16123" src="https://img.xiaohu.ai/2024/12/Jietu20241224-202620@2x-scaled.jpg" alt="" width="2560" height="1171" />以下是 LCM 的具体工作原理分解: <hr /> <h5><strong>1. 基础架构:概念嵌入的核心</strong></h5> <strong>概念的定义:</strong> <ul> <li style="list-style-type: none;"> <ul> <li>LCM 中的“概念”是语言和模态无关的语义单元,例如一个句子或一个完整的想法。</li> <li>每个概念在一个高维嵌入空间中表示,这个空间被称为 <strong>SONAR 嵌入空间</strong>。</li> </ul> </li> </ul> <strong>SONAR 嵌入空间:</strong> <ul> <li><strong>SONAR嵌入空间</strong>是一个多语言、多模态的语义嵌入系统它能将一句话(无论是文本还是语音)转化为一个高维度的数学表示(即一个“向量”)。 <ul> <li>这个“向量”是对句子含义的抽象表示,可以用来进行分析或生成新的内容。</li> <li><strong>高维语义嵌入</strong>:指这些表示包含了句子的主要信息,比如它的意思、语气、上下文关系等,而不是具体的单词。</li> <li>支持 200 多种语言(文本)和 76 种语言的语音,还可以扩展到其他模态(如手语)。</li> <li>把语言或语音数据编码成一个统一的、高度语义化的向量表示。</li> </ul> </li> </ul> <strong>如何工作?</strong> <ol> <li>输入:你给模型一个句子(比如“今天的天气真好”)或者一句话的语音。</li> <li>编码:SONAR系统会把这句话转换成一个向量(例如一个由数字组成的列表:<code>[1.2, -0.3, 0.5, ...]</code>)。 <ul> <li>这个向量不仅代表句子的意思,还能跨语言或模态使用。例如,这个向量可以同样适用于英语、法语、中文的表达。</li> </ul> </li> </ol> <strong>模型如何处理信息?</strong> <ul> <li>传统模型的做法: <ul> <li>逐字生成:从第一个单词“今天”开始,然后预测下一个单词“的”,再预测“天气”,依次生成。这种方式效率较低,生成长文本时容易出错。</li> </ul> </li> <li>LCM的做法: <ul> <li>LCM直接把整句话看作一个整体“概念”来处理,而不是逐个单词去生成。</li> <li>例如,如果想生成“今天的天气真好”,模型会预测整句话的语义向量(而不是逐个单词),然后直接还原为具体语言。</li> </ul> </li> </ul> <strong>为什么这种方式更高效?</strong> <ul> <li><strong>句子级别处理</strong>: <ul> <li>通过直接处理“句子”这种更高层次的单位,LCM可以避免逐字推测的低效和错误。</li> <li>例如,在写故事时,它可以先决定“这一段的主题是爱情”,然后生成具体内容。</li> </ul> </li> <li><strong>跨语言能力</strong>: <ul> <li>由于SONAR嵌入是语言无关的,LCM可以轻松地处理多语言任务。例如,中文的输入句子可以直接用SONAR表示,然后转化为英语输出。</li> </ul> </li> </ul> <h5><strong>2. 工作流程</strong></h5> LCM 的工作流程分为以下几个阶段: <strong>(1)输入处理</strong> <ul> <li><strong>多模态支持:</strong> <ul> <li>输入可以是文本、语音或其他模态的内容。</li> <li>使用 SONAR 编码器将输入分割成句子,并将每个句子转化为概念嵌入(语义向量)。</li> </ul> </li> </ul> <strong>(2)概念推理与生成</strong> <ul> <li><strong>概念序列处理:</strong> <ul> <li>LCM 使用类似 Transformer 的架构处理这些概念嵌入序列。</li> <li>根据输入的概念嵌入,模型生成下一步的概念嵌入。</li> </ul> </li> <li><strong>推理过程:</strong> <ul> <li>模型会基于前面的语义上下文,预测下一个概念嵌入。</li> <li>通过递归的方式,逐步生成完整的概念序列。</li> </ul> </li> </ul> <strong>(3)输出解码</strong> <ul> <li><strong>概念到语言:</strong> <ul> <li>使用 SONAR 解码器将概念嵌入解码为文本、语音等具体模态。</li> <li>解码器是语言无关的,可以根据需要生成不同语言或模态的输出。</li> </ul> </li> </ul> <hr /> <h5><strong>3. 多种建模方法</strong></h5> LCM 提供了三种主要的建模方式,每种方式适应不同任务和需求: <strong>(1)基础模型(Base-LCM)</strong> <ul> <li><strong>原理:</strong> 基于传统的回归方法(均方误差,MSE)直接预测下一步的概念嵌入。</li> <li><strong>特点:</strong> <ul> <li>简单直接。</li> <li>适合单一预测任务,但在生成多样性和复杂场景中表现稍逊。</li> </ul> </li> </ul> <strong>(2)基于扩散的 LCM(Diffusion-LCM)</strong> <ul> <li><strong>原理:</strong> 从噪声中逐步去除无关信息,生成语义向量嵌入。</li> <li><strong>扩散过程:</strong> <ol> <li><strong>前向扩散:</strong> 对输入嵌入逐步添加噪声,生成一个噪声序列。</li> <li><strong>反向去噪:</strong> 模型从噪声中逐步还原真实的语义嵌入。</li> </ol> </li> <li><strong>特点:</strong> <ul> <li>能够生成多个可能的语义结果。</li> <li>适合任务多样性较强的场景。</li> </ul> </li> </ul> <strong>(3)量化模型(Quantized-LCM)</strong> <ul> <li><strong>原理:</strong> 使用残差量化技术(Residual Vector Quantization, RVQ)将连续的语义嵌入表示转化为离散的向量单元。</li> <li><strong>特点:</strong> <ul> <li>生成更高效,适合需要控制多样性或随机性的任务。</li> </ul> </li> </ul> <hr /> <h5><strong>4. 高效性与模块化设计</strong></h5> <ul> <li><strong>高效性:</strong> <ul> <li>LCM 直接在概念层面操作,序列长度比传统模型短一个数量级,处理长文本更快。</li> <li>推理过程中,模型仅需预测概念序列,不需要对每个词元逐一处理。</li> </ul> </li> <li><strong>模块化:</strong> <ul> <li>编码器和解码器是独立的,支持独立优化。</li> <li>新语言或模态可以直接加入现有系统,而无需重新训练整个模型。</li> </ul> </li> </ul> <hr /> <h5><strong>5. 特殊能力:零样本推理</strong></h5> <ul> <li><strong>工作原理:</strong> <ul> <li>模型在预训练时已经涵盖了200多种语言和多种模态,因此在未见过的新语言或任务上也能表现优异。</li> <li>例如,用户输入一种未见过的语言,LCM 可以直接基于语义嵌入进行推理,无需微调。</li> </ul> </li> </ul> <h3><strong> 实验结果</strong></h3> <ol> <li><strong>生成质量</strong>: <ul> <li><strong>扩散模型 (Diffusion LCM)</strong> 在生成句子连贯性、上下文关联性和多样性上表现最佳,是最强大的架构。</li> <li>基础模型(Base-LCM)在精确性上有优势,但缺乏多样性和连贯性。</li> </ul> </li> <li><strong>与传统模型对比</strong>: <ul> <li><strong>LCM 在生成长文本和多语言任务中优于传统模型(如 GPT 和轻量化 LLaMA)</strong>,尤其在逻辑一致性和跨语言支持上表现突出。</li> </ul> </li> <li><strong>多样性和效率</strong>: <ul> <li>量化模型(Quantized LCM)在生成效率和多样性方面表现良好,适合资源受限的场景。</li> </ul> </li> <li><strong>最佳任务表现</strong>: <ul> <li><strong>生成长文本(如故事或论文)时,LCM 更连贯、更一致,适合复杂逻辑任务。</strong></li> <li>适配多语言和模态,能直接支持 200 种语言,无需额外微调。</li> </ul> </li> </ol> 论文:<a href="https://ai.meta.com/research/publications/large-concept-models-language-modeling-in-a-sentence-representation-space" target="_blank" rel="noopener">https://ai.meta.com/research/publications/large-concept-models-language-modeling-in-a-sentence-representation-space</a>






{kind=link}