

AnchorCrafter 是一个基于扩散模型的视频生成系统,专注于自动生成具有主播风格的产品宣传视频。该系统通过引入“人-物交互(HOI)”技术,在现有的人体姿态视频生成技术基础上,解决了生成过程中物体外观细节捕捉和人-物交互控制的挑战。
它可以用来制作那种“电商主播带货”风格的视频,比如你在淘宝、抖音或者YouTube上看到的那些主播介绍产品的短视频。
- 人和物体的互动视频生成
- 比如一个人拿着某个商品(手机、化妆品等)做动作,AnchorCrafter 可以自动生成这样的互动视频。
- 高清还原商品细节
- 无论商品是从什么角度拍摄的,它都能精准捕捉商品的外观、纹理和细节。
- 控制商品的运动轨迹
- 可以让商品“飞”起来或者与人物互动,比如抛接、摆放等动作。
它是用来干嘛的?
AnchorCrafter 的核心功能是:
- 让普通人的照片变成主播视频:比如你有一张自己的照片,它可以自动生成一个视频,让你“亲自”介绍产品,做出带货动作。
- 支持人和产品的互动:不像其他工具只能让人站着或摆姿势,这个系统会让“你”自然地拿起产品、展示、互动,比如拿着一部手机转一圈、或者把杯子递给“镜头”。
- 保持画面真实感:生成的视频不但人像逼真,产品的外观、细节和动作也非常真实,不会模糊或变形。
它解决了什么问题?
以前的AI生成视频工具,主要有以下问题:
- 人和物体不能互动:产品像是贴在屏幕上的图片,完全不“动”。
- 细节不真实:比如手拿着东西时,手和物体会“粘”在一起,看起来很假。
- 动作呆板:很难生成自然的动作,比如递物体或者展示细节。
AnchorCrafter 通过加入“人-物互动”的技术,让视频里的主播能自然地拿起、展示甚至旋转产品,还能精确控制产品的动作轨迹和角度,看起来就像真人拍摄的一样。
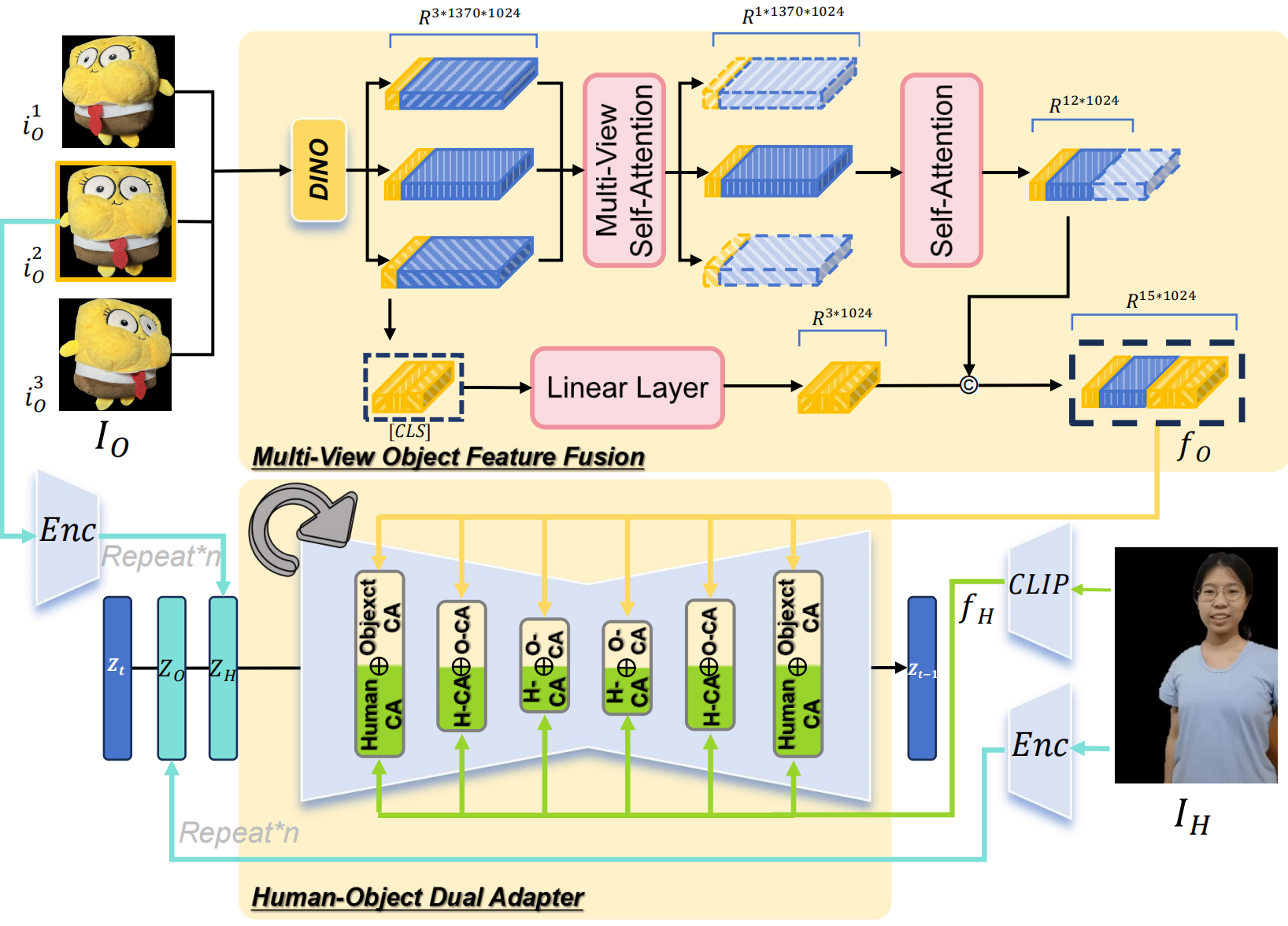
4.HOI-区域加权损失(HOI-Region Reweighting Loss)
- 功能:
- 在生成过程中对商品区域进行重点优化,提升商品细节的还原效果。
- 实现方法:
- 在训练时,通过加权损失函数,让模型对商品的细节(如边缘、纹理)给予更多关注。

实验结果
- 视频生成质量领先:
- AnchorCrafter 在视频质量指标(FID-VID)中大幅领先其他方法,生成的视频更加清晰流畅。
- 在物体动作的准确性(Object-IoU)和外观清晰度(Object-CLIP Score)方面,AnchorCrafter 的得分远高于现有方法,表明它在物体外观细节和运动轨迹控制上表现最佳。
- 用户评价高度认可:
- 用户测试结果表明,AnchorCrafter 在人物和物体外观保持、动作自然性,以及视频整体质量上均获得最高评分,尤其在物体与手部交互细节方面表现突出。
- 模块的重要性验证:
- 消融实验显示,多视角特征融合、手部3D网格、以及区域重加权损失模块对生成质量至关重要,缺少任何模块都会导致物体外观模糊或交互不自然。
- 超越现有方法:
- 与 AnimateAnyone、MimicMotion 等方法相比,AnchorCrafter 在所有指标上均有显著提升,特别是在人-物交互动作的真实感和一致性上表现卓越。














{kind=link}