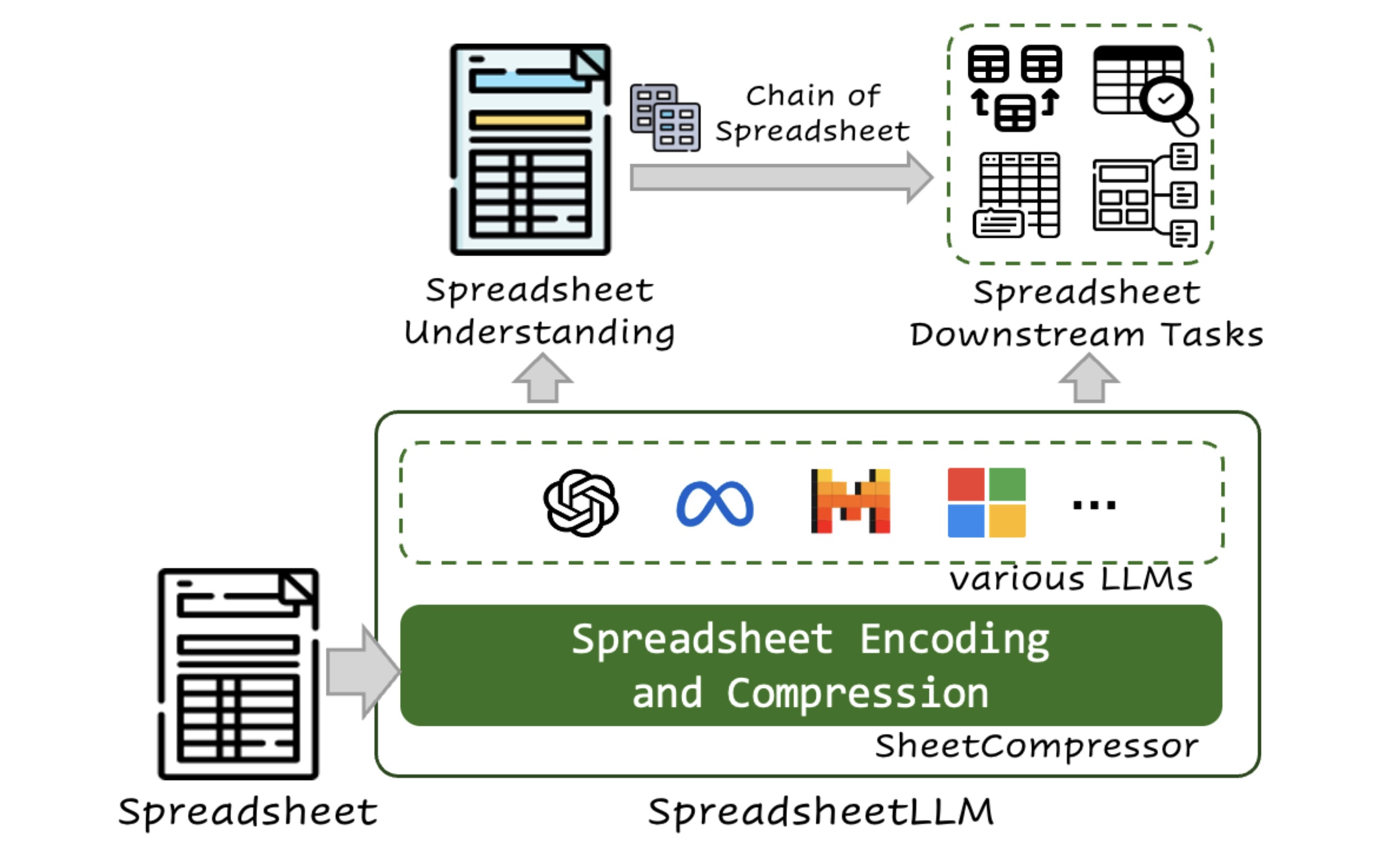
微软研究团队提出了一种新的方法,旨在帮助大语言模型(如GPT-4)更好地理解和处理电子表格数据。传统方法在处理电子表格时往往受到token限制,并且难以有效解析电子表格的二维布局和复杂结构。 <strong>解决的问题</strong> 在处理电子表格数据时,LLMs(大语言模型)面临以下几个主要问题: <ol> <li><strong>Token限制</strong>:大多数LLMs处理数据的token数量有限,而电子表格通常包含大量数据,容易超过这些限制。</li> <li><strong>二维布局复杂性</strong>:电子表格的二维结构和布局不适合LLMs的线性和顺序输入方式。</li> <li><strong>数据冗余</strong>:电子表格中包含大量重复值和空单元格,这导致LLMs处理效率低下。</li> </ol> <img class="aligncenter size-full wp-image-11368" src="https://img.xiaohu.ai/2024/07/Jietu20240716-192548@2x.jpg" alt="" width="2526" height="1562" />研究人员开发了SPREADSHEETLLM框架,通过三个主要步骤来解决这些问题: <ol> <li><strong>结构锚点压缩</strong>:识别并保留表格边界的重要行和列,删除不重要的重复行和列,从而减少数据量。</li> <li><strong>倒排索引翻译</strong>:将电子表格中的相同数据合并,减少重复数据,优化数据结构。</li> <li><strong>数据格式聚合</strong>:根据单元格的数据格式,将相同格式的数据聚合在一起,进一步减少数据量。</li> </ol> 实验结果表明,这种方法显著提高了模型在电子表格表格检测和问答任务中的性能,同时大大减少了处理所需的计算资源。该框架在电子表格表格检测任务中的性能相比基础方法提高了25.6%,并且在F1评分上达到了78.9%,超过了现有最好的模型12.3%。 <h3>SHEETCOMPRESSOR 详细方法介绍</h3> <h4><img class="aligncenter size-full wp-image-11369" src="https://img.xiaohu.ai/2024/07/Jietu20240716-192532@2x.jpg" alt="" width="2454" height="1090" />1. 结构锚点压缩(Structural Anchor-based Compression)</h4> <strong>方法概述</strong>: <ul> <li>电子表格通常包含大量的同质行和列,这些行和列对理解表格的布局和结构贡献有限。</li> <li>通过识别电子表格中的异质行和列(即结构锚点),我们可以提取出包含关键信息的“骨架”版本,并删除冗余部分。</li> </ul> <strong>具体步骤</strong>: <ol> <li><strong>识别结构锚点</strong>: <ul> <li>确定表格边界处的异质行和列,这些行和列通常包含重要的表头信息或数据分隔。</li> <li>使用启发式方法,例如基于单元格值、合并单元格、边框和填充颜色的差异,来识别这些锚点。</li> </ul> </li> <li><strong>提取骨架版本</strong>: <ul> <li>移除远离锚点的同质行和列,保留近距离的锚点行和列。</li> <li>对提取出的骨架版本进行坐标重映射,以确保单元格坐标的连续性和数据关系的完整性。</li> </ul> </li> </ol> <strong>效果</strong>: <ul> <li>通过移除冗余行和列,显著减少了电子表格的数据量。</li> <li>保留了表格的关键信息和结构,有助于模型更好地理解和处理电子表格。</li> </ul> <h4>2. 倒排索引翻译(Inverted-Index Translation)</h4> <strong>方法概述</strong>: <ul> <li>电子表格中经常包含大量的空单元格和重复值,传统的编码方法需要记录所有这些单元格,导致token使用效率低下。</li> <li>通过倒排索引方法,可以有效地压缩这些数据。</li> </ul> <strong>具体步骤</strong>: <ol> <li><strong>矩阵编码转换为字典格式</strong>: <ul> <li>将传统的基于矩阵的编码方法转换为字典格式,其中单元格值作为键,地址作为值。</li> <li>例如,将单元格地址和值对 <code>{Addressi,j : Value}</code> 转换为 <code>{Value : [Address1, Address2, ...]}</code>。</li> </ul> </li> <li><strong>合并相同值的单元格</strong>: <ul> <li>将具有相同值的单元格地址合并为地址范围,排除空单元格,优化token使用。</li> </ul> </li> </ol> <strong>效果</strong>: <ul> <li>通过合并相同值的单元格和排除空单元格,显著减少了token的使用量。</li> <li>保留了数据的完整性和结构,有助于模型更高效地处理电子表格。</li> </ul> <h4>3. 数据格式聚合(Data Format Aggregation)</h4> <strong>方法概述</strong>: <ul> <li>电子表格中相邻的单元格通常共享相同的数据格式(例如数字格式、日期格式等)。</li> <li>通过聚合这些相邻单元格,可以进一步压缩数据量,同时保留数据的语义信息。</li> </ul> <strong>具体步骤</strong>: <ol> <li><strong>提取数字格式字符串(NFS)</strong>: <ul> <li>使用工具(如ClosedXML或OpenPyXL)提取单元格的内置格式字符串。</li> <li>例如,“2024.2.14”的NFS为“yyyy-mm-dd”。</li> </ul> </li> <li><strong>规则识别数据类型</strong>: <ul> <li>使用预定义规则,将单元格值映射到特定的数据类型(如年份、整数、浮点数、百分比等)。</li> <li>聚合具有相同格式或类型的相邻单元格,简化表示。</li> </ul> </li> </ol> <strong>效果</strong>: <ul> <li>通过聚合相同格式和类型的单元格,减少了token的使用量。</li> <li>提供了简化且高效的表示形式,有助于模型更好地理解和处理数值数据。</li> </ul> <h3>实验结果</h3> <h4>压缩率分析</h4> SHEETCOMPRESSOR显著减少了处理电子表格所需的tokens。在测试数据集中,结合所有三个模块(结构锚点压缩、倒排索引翻译和数据格式聚合),压缩率最高,达到24.79倍。这意味着,通过这些方法,电子表格的数据量被大幅减少,从而提高了处理效率。 <h4><img class="aligncenter size-full wp-image-11367" src="https://img.xiaohu.ai/2024/07/Jietu20240716-192609@2x.jpg" alt="" width="1252" height="1294" />电子表格表格检测</h4> 在电子表格表格检测任务中,使用SHEETCOMPRESSOR后的GPT-4模型在所有数据集上均表现优异,尤其是在处理大型和超大数据集时,F1分数显著提高。相比于未使用压缩方法的模型,性能提升明显。 开源模型如Llama3和Mistral-v2在使用压缩方法后,F1分数也大幅提升,这表明SHEETCOMPRESSOR对各种LLMs都有显著的性能增强作用。 模块消融实验表明,结构锚点压缩模块对保留关键结构信息至关重要,去除该模块后F1分数显著下降。倒排索引翻译和数据格式聚合模块对性能也有贡献,但不如结构锚点压缩模块重要。 <h4><img class="aligncenter size-full wp-image-11371" src="https://img.xiaohu.ai/2024/07/Jietu20240716-193754@2x.jpg" alt="" width="1220" height="426" />电子表格问答</h4> 在电子表格问答任务中,使用SHEETCOMPRESSOR后的GPT-4模型表现显著提升,准确率达到74.3%。经过微调后的模型在处理复杂的电子表格问答任务时表现尤为出色,准确率显著高于未使用压缩方法的模型。 <img class="aligncenter size-full wp-image-11370" src="https://img.xiaohu.ai/2024/07/Jietu20240716-193801@2x.jpg" alt="" width="1136" height="558" /> 论文:<a href="https://arxiv.org/pdf/2407.09025" target="_blank" rel="noopener">https://arxiv.org/pdf/2407.09025</a>






{kind=link}