

OpenAI 开发了一种名为 CriticGPT 的模型,该模型基于 GPT-4,用于帮助发现 ChatGPT 生成代码中的错误。CriticGPT 会对 ChatGPT 的回答进行批评,指出其中的错误,这样可以帮助人工训练师更有效地发现问题,并在从人类反馈中进行强化学习(RLHF)时提高准确性。通过将 CriticGPT 整合到 RLHF 标注流程中,可以增强 AI 生成的批评的准确性和全面性,从而改进 ChatGPT 的整体表现和对齐度。
-
人类评估的局限性:当前的LLM模型如ChatGPT等,在生成复杂代码时,即使是经验丰富的专家也难以可靠地评估其输出的质量和正确性。CriticGPT通过训练模型生成自然语言评论,帮助人类更准确地评估代码,从而弥补了人类评估的局限性。
-
提高错误检测能力:模型生成的代码往往包含错误,这些错误可能未被人类评估者发现。CriticGPT在检测这些错误方面表现出色,研究发现其检测到的错误数量比人类承包商更多。
-
减少偏见和幻觉:虽然CriticGPT也有可能产生幻觉错误,但通过与人类合作(即人机合作团队),能够显著减少这些幻觉,同时保持高效的错误检测能力。
研究发现,在CriticGPT的帮助下,人们审查ChatGPT代码的表现比没有帮助时高出60%。
 CriticGPT的主要功能
CriticGPT的主要功能
1. 错误检测
CriticGPT能够识别代码中的各种错误,包括语法错误、逻辑错误和安全漏洞。通过全面分析代码,它可以生成包含所有明显和严重错误的评论,并确保没有遗漏任何重要问题。同时,CriticGPT在生成评论时,会避免幻觉错误和不必要的挑剔问题。
功能描述:
- CriticGPT被训练来识别ChatGPT生成代码中的各种错误,包括语法错误、逻辑错误和功能性错误。
- 它能够自动扫描代码,发现不符合预期或有潜在问题的部分,并标注出来。
应用示例:
- 在代码生成或审查过程中,CriticGPT可以作为辅助工具,快速标记出需要注意和修正的错误。
2. 批评性评论生成
CriticGPT能够接受一个代码片段和其预期功能描述,并生成详细的自然语言评论。这些评论指出代码中的潜在错误,并提供改进建议。例如,它可能会指出某个代码段的安全漏洞,并建议使用更安全的方法。
功能描述:
- CriticGPT不仅识别错误,还能够生成详细的批评性评论,解释错误的性质和可能的影响。
- 评论包括错误的具体位置、错误的类型、发生的原因以及可能的修正建议。
应用示例:
- 在代码审查会议中,CriticGPT提供详细的错误解释和改进建议,帮助团队成员更好地理解和解决问题。
3. 增强训练效果
功能描述:
- 通过与CriticGPT协作,训练师能够生成比单独工作时更全面的评论。研究显示,当人类与CriticGPT共同工作时,评论的质量和覆盖范围都有所提高。
- CriticGPT可以增强训练师的能力,使其能够更有效地识别和修正复杂问题。
应用示例:
- 在AI模型训练中,训练师利用CriticGPT的反馈,提高对模型生成内容的审核和改进效率。
4. 减少虚假错误
CriticGPT在生成评论时采用强制采样束搜索(FSBS)策略,通过强制采样生成多种评论,并选择得分最高的评论。这种方法确保生成的评论既全面又减少幻觉错误,使得评论的质量和准确性得到显著提升。
功能描述:
- CriticGPT在生成批评性评论时,能够减少对不存在问题的“虚假错误”的标注。相比独立工作的模型,CriticGPT的评论更为准确,避免了不必要的干扰。
应用示例:
- 在日常代码维护和优化中,CriticGPT提供准确的错误报告,减少了开发者在无关问题上浪费的时间。
5. 模型训练与优化
CriticGPT生成的评论会根据其全面性、错误包含率、幻觉和挑剔的出现频率以及总体主观有用性进行评价和比较。通过这些评价指标,能够确定哪些评论对发现和解决问题最有帮助,从而不断优化和改进模型的性能。
功能描述:
- CriticGPT本身通过RLHF(从人类反馈中进行强化学习)进行训练,特别是通过处理包含错误的输入并生成批评性反馈。
- 训练过程中,人类训练师会插入故意的错误,让CriticGPT识别并批评,这帮助模型学习如何准确地指出和解释错误。
应用示例:
- 在开发新版本的AI模型时,使用CriticGPT进行内部测试和优化,确保模型在正式发布前已尽可能减少错误。
6. 精确搜索与评估
功能描述:
- CriticGPT通过精确搜索与评估机制,能够在测试时平衡对问题的积极查找和减少误报之间的关系。这使得生成的评论更具针对性和实用性。
应用示例:
- 在大型项目中,使用CriticGPT对代码进行全面审核,提供详尽且精准的错误报告,为项目的顺利推进保驾护航。
7. 人类与AI协作增强
CriticGPT可以作为辅助工具,在评估过程中预填充初始评论,帮助人类评估者更快、更准确地识别问题。通过与人类评估者协同工作,CriticGPT能够生成更全面的评论,并减少幻觉和挑剔问题,显著提高评估效率和准确性。
功能描述:
- CriticGPT的设计初衷之一是增强人类与AI的协作效果,通过AI辅助人类训练师,使得他们在评估和修正AI输出时更为高效和准确。
应用示例:
- 在教育和培训新手程序员时,CriticGPT提供实时的反馈和建议,提高学习效果和代码质量。
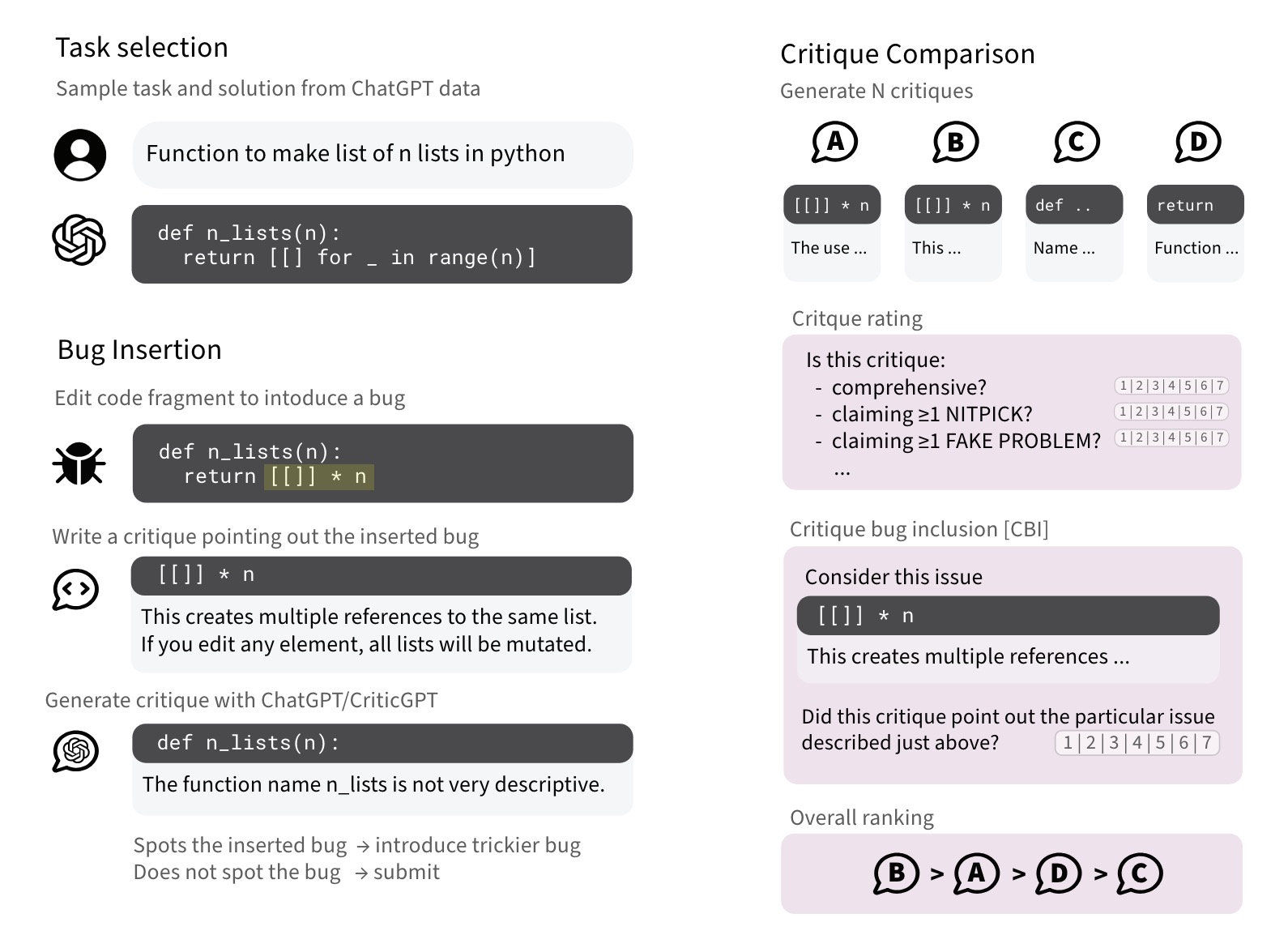 技术方法
技术方法
CriticGPT 也是通过强化学习从人类反馈(RLHF)进行训练的,但它的训练内容主要是包含错误的输入,专门用于进行批判性评估。研究人员会人为地在 ChatGPT 生成的代码中插入错误,然后编写这些错误代码的反馈,以此来训练 CriticGPT。实验结果表明,在有63%的情况下,训练师更喜欢 CriticGPT 提供的批评,而不是 ChatGPT 的批评。部分原因是 CriticGPT 减少了对细枝末节的“挑剔”以及虚构的问题数量,使得批评更为有效和准确。
- RLHF 训练:
- CriticGPT 和 ChatGPT 类似,通过强化学习从人类反馈(RLHF)进行训练。
- 训练过程中,CriticGPT 主要处理包含错误的输入,并进行批判性评估。
- 错误插入:
- 研究人员手动在 ChatGPT 生成的代码中插入错误,创建包含错误的输入数据。
- 人类训练师编写这些插入错误的代码反馈,就像他们发现了这些错误一样。
- 批评示例对比:
- 相同的人类训练师会对多个批评示例进行比较,以判断哪些批评能够准确捕捉插入的错误。
- 这种方法确保了训练师能够识别并评估不同批评的有效性。
- 自然发生错误与插入错误:
- 研究同时考察 CriticGPT 能否捕捉到插入错误和之前训练师已经发现的自然发生错误。
- 结果显示,CriticGPT 对自然发生错误的批评在63%的情况下被认为优于 ChatGPT,主要原因在于 CriticGPT 减少了不必要的“小毛病”批评和虚构问题。
- 搜索与平衡:
- 在测试过程中,使用额外的搜索机制对批评奖励模型进行搜索,以平衡检测错误的激进程度和精确度。
- 这种搜索过程允许在减少虚构错误和检测错误数量之间进行权衡,生成尽可能有助于 RLHF 的批评。
实验结果
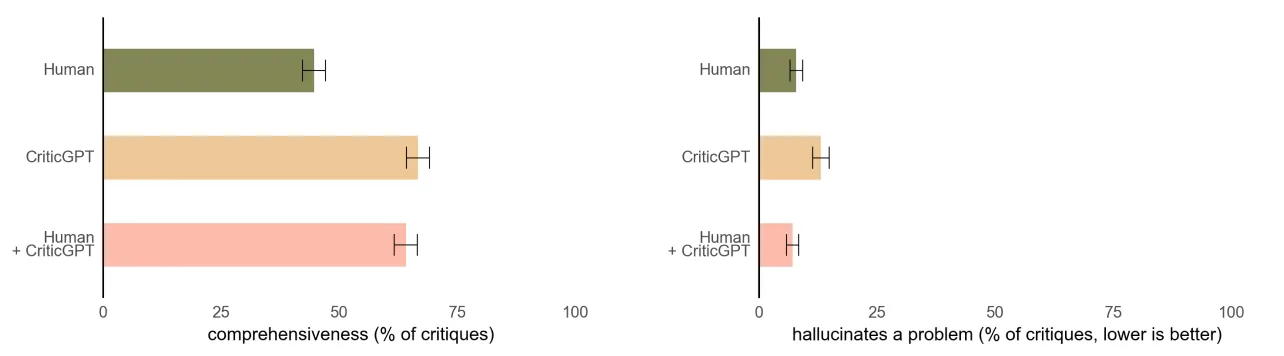
- 批评的偏好度:
- 在实验中,当训练师使用 CriticGPT 提供的批评时,63% 的情况下,他们更喜欢 CriticGPT 的批评而不是 ChatGPT 的批评。
- 这种偏好主要因为 CriticGPT 减少了不必要的“小毛病”挑剔(即细枝末节的无关紧要的批评)和虚构的问题(即模型凭空想象出来的错误)。
- 人类与 CriticGPT 团队的效果:
- 实验中,第二名随机选择的训练师更倾向于人类与 CriticGPT 组合团队的批评,而不是单独由人类做出的批评,超过 60% 的时间里都是如此。
- 这种结果显示出 CriticGPT 在帮助人类训练师进行批评时,能显著提升他们的效果。
- 减少虚构错误和挑剔:
- CriticGPT 的批评中,虚构错误和“小毛病”挑剔的数量显著减少,这使得批评质量和有效性得到了提升。
- 这种减少虚构错误和挑剔的方法,使得批评更加精准,帮助训练师更好地发现真正的问题。
原文:https://openai.com/index/finding-gpt4s-mistakes-with-gpt-4/
论文:https://cdn.openai.com/llm-critics-help-catch-llm-bugs-paper.pdf













{kind=link}