
Multimodal ArXiv是一个旨在提高大型视觉语言模型(LVLMs)科学理解能力的数据集项目。该项目由香港大学和北京大学的研究者共同进行,包含两个主要部分:ArXivCap和ArXivQA
ArXivCap
- 功能与内容:
- 这是一个图形-标题数据集,包含6.4M图像和3.9M标题。
- 数据源自572K篇覆盖各科学领域的ArXiv论文。
- 旨在通过提供丰富的科学图像和相关标题,改善大型视觉-语言模型(LVLMs)对抽象图像(如几何形状和科学图表)的理解能力。
- 通过保留子图结构和原始论文的标题,支持多样化的评估任务,为LVLMs提供了解释复杂科学概念的能力。
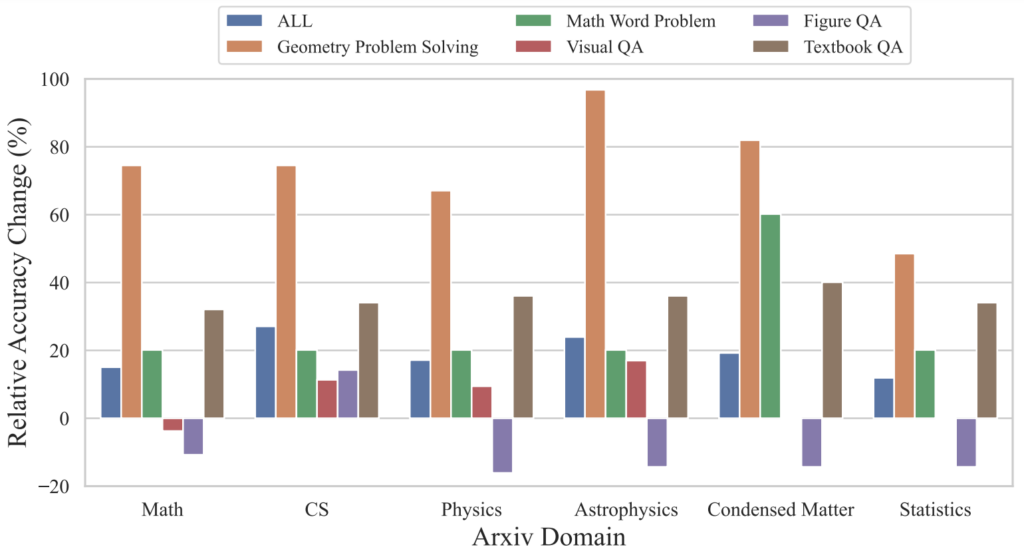
ArXivQA
- 功能与内容:
- 这是一个通过基于科学图形提示GPT-4V生成的问答数据集。
- 旨在显著增强LVLMs的数学推理能力。
- 在一个多模态数学推理基准测试上实现了10.4%的绝对准确率提升。
- 通过生成的问答对,测试和提升模型在科学领域的推理能力,特别是在数学和逻辑推理方面。
共同目标:这两个数据集共同目标是弥补科学领域训练数据集的不足,从而提升LVLMs在解释科学图表和进行科学推理方面的能力。通过ArXivCap的图形-标题对和ArXivQA的问答对,多模态ArXiv数据集旨在为LVLMs提供丰富的科学文本和视觉信息,以支持更深入的学习和更准确的科学理解。