
大语言模型(LLMs)在数学问题解决和代码生成等推理和科学领域展现了强大的能力。然而,当前的LLMs在“自我纠正”能力方面表现不佳,尤其是缺乏外部输入的情况下,无法有效地检测和修正自己的错误。这种“自我纠正”能力在没有外部监督的情况下显得尤为重要,因为LLMs往往具备完成任务所需的知识,但不能有效地调用和推理这些知识来修正错误。
Google DeepMind 研究人员开发的一种新方法,称为SCoRe,旨在提高大型语言模型(LLMs)在复杂任务中的自我纠正能力,特别是数学推理和编程任务。
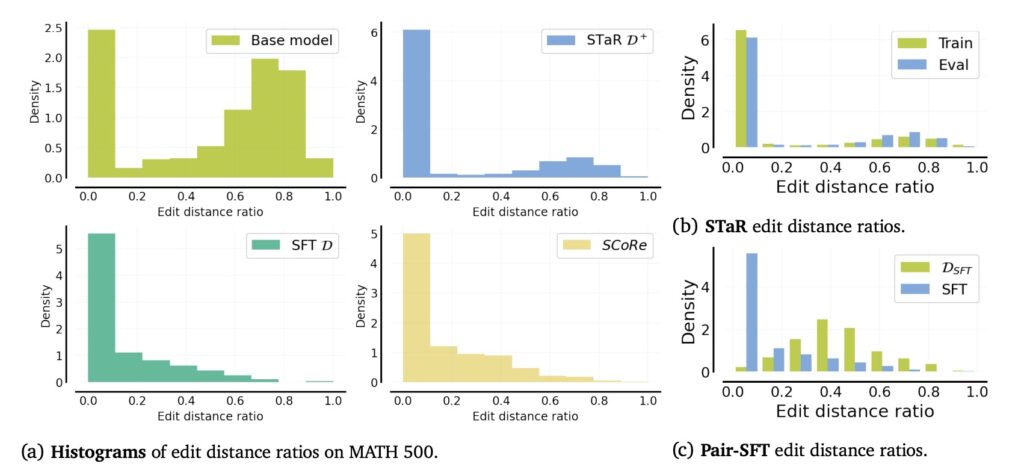
大语言模型(LLMs)在数学问题解决和代码生成等推理和科学领域展现了强大的能力。然而,当前的LLMs在“自我纠正”能力方面表现不佳,尤其是缺乏外部输入的情况下,无法有效地检测和修正自己的错误。这种“自我纠正”能力在没有外部监督的情况下显得尤为重要,因为LLMs往往具备完成任务所需的知识,但不能有效地调用和推理这些知识来修正错误。
Google DeepMind 研究人员开发的一种新方法,称为SCoRe,旨在提高大型语言模型(LLMs)在复杂任务中的自我纠正能力,特别是数学推理和编程任务。