
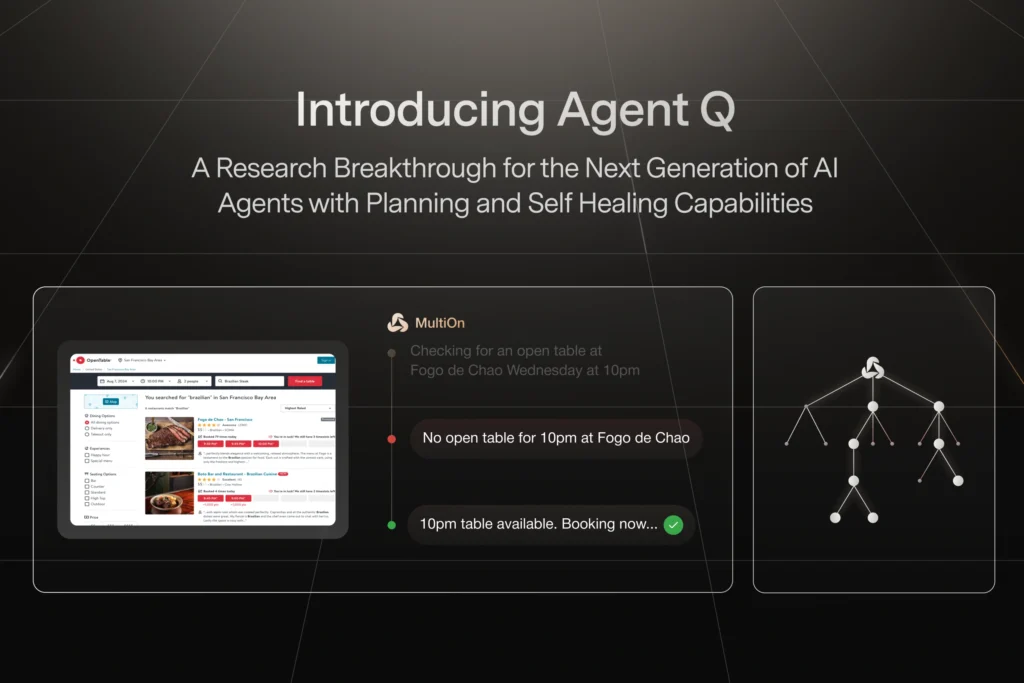
MultiOn 推出了一种新型自主 AI 代理 Agent Q。Agent Q,一个自监督的代理推理和搜索框架,可以通过自我对弈和强化学习在真实环境中自主改进。
Agent Q 是一个全新的自监督代理推理和搜索框架,经过六个月的开发后正式发布。该框架专注于通过自我对弈和强化学习(RL)在真实任务和互联网环境中自主改进。它利用了当前最先进的大语言模型(LLM)来处理网页内容,创建任务计划,并以自然语言形式进行推理,尤其适用于长时间跨度的任务执行。
Agent Q具有高级规划和自愈能力。它结合了蒙特卡洛树搜索(MCTS)、AI 自我批评和基于人类反馈的强化学习(RLFH)等前沿技术,使 AI 能够在动态环境中进行复杂的多步推理和决策。
想象一下,你在一个非常大的迷宫中寻找出口,这个迷宫里有很多分岔路,而且每条路可能会带你走得更远或更接近出口。Agent Q 就像是一个非常聪明的助手,它不仅能帮你分析每条路的可能性,还能在走错路时自我反省,下次避免犯同样的错误。
Agent Q 解决了什么问题:
- 静态数据集的局限性: 传统的LLMs在静态数据集上的监督训练虽能在自然语言任务中表现优异,但在需要多步骤决策的动态互动环境(如网络导航)中,表现出较差的泛化能力。这导致模型在面对复杂任务时无法自主有效地作出决策,容易产生复合错误,导致次优的结果。
- 多步推理和复合错误: 在多步决策任务中,模型往往难以处理长时间跨度的任务,因为环境中的奖励信号较为稀疏,且一旦在某一步中出错,就很难纠正,这使得整体决策过程不够稳健。Agent Q 通过引入自我批评和引导搜索,减少了这种复合错误的影响,提高了任务成功率。
- 复杂环境中的适应性: 传统的 AI 代理在复杂和动态环境中通常表现不佳,无法灵活应对变化。Agent Q 通过整合多种前沿算法,增强了 AI 在复杂环境中的适应性和决策能力。
为了应对复杂的多步骤环境,Agent Q 引入了树搜索能力,使代理能够在网页上进行多层次的深入搜索,从而纠正可能出现的错误。这一搜索过程由过程监督所驱动,代理在每一步提出可能的行动,并通过一个批判模型对这些行动进行排序。这种批判模型的作用是作为一种生成价值函数,标志着未来技术的发展方向。
此外,Agent Q 还利用了零样本视觉语言模型(VLM)进行结果监督,以推理和验证任务是否成功。在实验中,研究团队使用了GPT-4V,并希望未来能整合多模态LLaMa,因为视觉元素对任务的准确性至关重要。
在实际应用中,Agent Q 使用蒙特卡罗树搜索(MCTS)在网页上进行搜索,大幅提升了代理的性能。团队还部署了一个强化学习循环,将树搜索的监督反馈到基础代理中,从而进一步提高零样本性能。在模拟中,Agent Q 在零样本评估中表现优于GPT-4,并在推理时间的搜索中与人类表现相当。更重要的是,Agent Q 成功应用于在线网站的实际预订任务中,在这种复杂环境下表现出了卓越的自主改进能力。
然而,尽管取得了显著的进展,仍有许多研究问题需要解决。例如,团队目前使用了冻结的零样本生成批判模型,但未来需要研究如何通过训练对其进行微调或改进。此外,尽管进行了大量的强化学习训练,零样本性能与搜索性能之间仍存在明显差距,找出这一差距的原因是未来研究的重点之一。
另外,Agent Q 的研究还探讨了最合适的搜索方法。在现有工作中使用了蒙特卡罗树搜索和A*算法,未来可能通过强化学习发现新的、更好的搜索方法,以实现代理的自我纠正和探索。最后,团队还面临如何在互联网大规模部署中确保安全性的挑战,因为尽管模型能够自我纠正并最终完成任务,但可能无法修复其错误带来的后果。因此,如何利用用户反馈、人类参与以及安全批判来进行模型训练,将是未来研究的重要方向。
- 框架功能: Agent Q 利用当前一代大型语言模型(LLM)的理解能力,处理网页内容,创建任务计划,并用自然语言进行推理。这种框架专注于长时间跨度的任务执行。
- 树搜索能力: 为应对复杂的多步骤环境,Agent Q 采用了树搜索功能,使代理能够在网页上进行深入的多层次搜索,帮助纠正潜在错误。
- 过程监督与生成批判: Agent Q 的搜索过程受到过程监督的驱动。每个步骤中,代理提出可能的行动,然后通过一个批判模型对这些行动进行排序,以评估其前景,这种批判模型作为一种生成价值函数,标志着未来的发展方向。
- 结果监督与视觉模型: Agent Q 还采用了零样本视觉语言模型(VLM)进行结果监督,以推理和验证任务的成功与否。实验中使用了GPT-4V,未来希望整合多模态LLaMa,视觉元素对准确性至关重要。
- 蒙特卡罗树搜索(MCTS)与强化学习: Agent Q 使用蒙特卡罗树搜索(MCTS)在网页上进行搜索,显著提升了代理性能。同时,还部署了一个强化学习循环,将树搜索的监督反馈到基础代理中,进一步提升零样本性能。
- 模拟与实际应用: 在模拟中,Agent Q 在零样本评估中表现优于GPT-4,并在推理时间的搜索中与人类表现相当。此外,Agent Q 成功应用于在线网站的实际预订任务,表现出色。
- 模型改进与研究问题: 微调后的LLaMa 70B模型在零样本性能上显著超过了GPT-4。经过一天的自主对弈,性能从18.6%跃升至81.7%,在线搜索的成功率更是达到95.4%。不过,仍有许多研究问题需要解决,包括如何改进生成批判模型、探索更好的搜索方法,以及如何应对大规模部署中的安全性挑战。
Agent Q 的主要能力包括:
- 高级规划能力:
- 多步推理: Agent Q 能够在复杂的任务中进行多步推理,通过规划和执行多个步骤来完成目标任务。它能够有效地在动态环境中做出决策,并灵活调整策略以适应不断变化的情况。
- Agent Q 能够在复杂的、需要多步骤决策的任务中表现出色。这种能力使得模型不仅能够生成文本,还能在互动环境中执行一系列动作,例如在网站导航、预订等场景中逐步完成任务。通过结合MCTS搜索和DPO算法,Agent Q 能够更好地规划和执行复杂任务。
- 自愈能力:
- AI 自我批评: Agent Q 在执行任务的每一步都会进行自我评估,并根据反馈调整自己的行为。这种自愈能力使得 Agent Q 能够在遇到错误或障碍时自行纠正,避免陷入不利的决策路径。
- 通过自我批评机制,模型可以在每个决策步骤中生成中间反馈,这帮助模型在面对长时间跨度和复杂路径的任务时进行更为精确的探索和决策。此能力确保模型能够持续改进其决策策略。
- 引导搜索(Guided Search):
- 蒙特卡洛树搜索(MCTS): Agent Q 利用 MCTS 技术进行决策,它能够通过探索不同的行动路径,平衡探索与利用,找到最优的行动序列。这使得 Agent Q 能够在未知或复杂的网页导航任务中生成多样化和最优的解决方案。
- MCTS帮助模型在面对复杂决策树时,能够平衡探索新的可能路径与利用已知的高回报路径,从而找到最优解。这使得模型在面对具有高复杂性和不确定性的任务时,能够提高成功率。
- 基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLFH):
- 直接偏好优化(DPO): Agent Q 通过 DPO 算法,从人类反馈中学习最佳决策。该算法使 Agent Q 能够有效利用包括次优路径在内的各种数据进行训练,从而在复杂环境中提高成功率。
- 这种学习机制允许模型优化其策略,不仅依赖于成功的案例,还可以从失败中提取有用的信息,从而避免未来的类似错误。这种能力使得模型具有更强的鲁棒性和适应性。
- 自动改进与自我优化能力
- Agent Q 可以通过自主探索和在线学习不断改进其决策策略。通过MCTS和DPO算法的结合,模型能够在有限的监督下自主改进,逐步提升其任务执行能力。这种自动化的改进机制使得Agent Q能够适应新的任务和环境。
- 在线搜索与动态环境适应能力
Agent Q 在实时环境中具有执行在线搜索的能力,这大幅提升了模型在动态环境中的表现。在面临不断变化的信息或环境时,模型能够实时调整其决策策略,从而确保任务的高效完成。